《Kubernetes Up & Running Third Edition》
Kubernetes官网:https://kubernetes.io/docs/home/
Kubernetes中文官网:https://kubernetes.io/zh-cn/docs/home
《Kubernetes即学即用》第三版,作者的话 Dive into the Future of infrastructure(深入未来基础设施的世界)。
Kubernetes是一个用于部署容器化应用程序的开源编排器。
Kubernetes旨在极大地简化构建、部署和维护分布式系统地任务,它收到了数十年来 构建可靠系统地实际经验的启发,并且从头开始设计,以使这种体验至少是愉快的。
从最早的编程语言,到面向对象编程,再到虚拟化和云基础设施的发展,计算机科学的历史, 本质上就是不断创造抽象层的历史,这些抽象层的作用,是隐藏底层复杂性,让开发者 能够构建越来越复杂、越来越强大的应用程序。
容器以及像 Kubernetes 这样的容器编排API,已经被证明是一种重要的抽象层, 能够从根本上简化可靠、可扩展的分布式系统的开发。
说人话:
开发者不用天天跟服务器配置斗智斗勇,可以把精力放在程序本身,现实世界依旧会把你来回地面, 比如 YAML 写错一个空格,整个集群一起罢工。
前几章讲概念、中间讲对象、后面讲安全 存储 扩展、最后讲多集群。
Kubernetes 本质就三件事
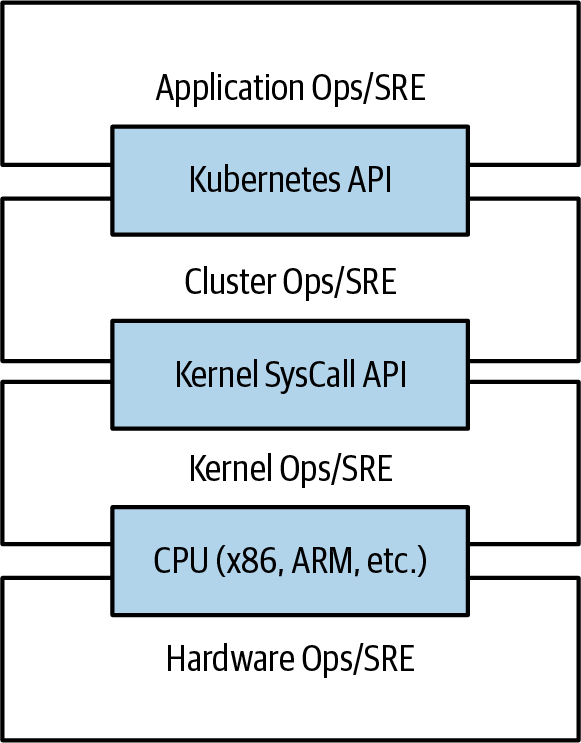
提到 “可靠、可扩展的分布式系统”时。
如今越来越多的服务通过网络以API的形式提供,这些API通常由一个 分布式系统 来 实现,实现API的各个组件运行在不同的机器上,通过网络连接,并通过网络通信来 协调彼此的行为。
同样,在 软件发布(rollout)或其他 维护操作 期间,系统也必须保持可用性。
系统还必须具备 高度的可扩展性,能够随着使用量的持续增长而扩展容量,而不需要对 实现服务的分布式系统进行彻底的重新设计。意味着系统可以自动扩展或缩减容量, 从而使应用程序保持最高的资源使用效率。
速度几乎是当今所有软件开发中的核心要素。软件行业已经从过去通过盒装 CD 或 DVD 发布产品,演变为通过网络提供的 基于 Web 的服务,并且这些服务可能每小时都会更新。
与竞争对手之间的差距,往往体现在以下方面:
速度不是单纯的“快”,更在意 服务必须高度可靠
过去时代,每天午夜进行更新、服务短暂下线是可接受的,今天用户期望服务始终在线。
真正的速度:在不影响可用性的情况下持续发布软件的能力。
容器和Kubernetes鼓励开发人员构建遵循 不可变基础设施(Immutable Infrastructure)原则的分布式系统, 在不可变基础设施中,一旦系统中的某个构件(artifact)被创建出来,就不再通过用户修改进行改变。
在许多系统中,这些增量修改不仅来自系统升级,还来自运维人员的手动更改。此外,在由大型团队运行的系统中,这些更改很可能由许多人完成,而且在很多情况下根本没有任何记录。
在不可变系统中,更新并不是一系列增量修改。相反,会构建一个全新的完整镜像,然后通过一次操作直接用新镜像替换旧镜像。
两种升级软件方式对比:
方案一:
方案二:
不可变的容器镜像是 Kubernetes 中一切工作的核心,“不要修改服务器,直接换服务器”。
声明式配置(Declarative Configuration),在 Kubernetes 中,一切都是声明式配置对象(declarative configuration object),它表示系统的期望状态(desired state)。
Kubernetes 的任务就是确保现实中的实际状态与这个期望状态保持一致。
命令式配置与声明式配置的区别:
简单例子,假设想让某个软件运行3个副本
命令式方式会写成:
运行A
运行B
运行C而声明式方式则会写成,“我需要三个副本”:
replicas = 3把声明式配置存储在版本控制系统中的做法通常被称为:基础设施即代码(Infrastructure as Code,IaC)
叫 GitOps 的理念开始把 Infrastructure as Code 的时间进一步规范化,核心思想
把Git仓库当作唯一的真实来源(source of truth)。
当你采用GitOps时,对生产环境的所有修改都通过向 Git 仓库提交代码完成,自动化系统会把这些修改同步到 Kubernetes 集群中。
当声明式配置 + 版本控制系统结合时,再加上 Kubernetes 能自动让现实状态匹配声明状态,回滚(rollback)就变得非常简单。
自愈系统(Self-Healing Systems)
传统系统:
系统挂了 -> 告警 -> 运维被电话吵醒 -> 登录 -> 修Kubernetes:
系统挂了 -> 控制器发现状态不对 -> 自动拉起新 Pod从 半夜修服务器 到 写YAML。
随着产品不断增长,不可避免地需要同时扩展软件系统本身,以及开发这些软件的软对规模。
Kubernetes 可以在这两个方面提供帮助。系统被拆成一堆相对独立的小组件,它们之间通过明确的接口通信。
把一个巨大复杂的东西拆成很多小块,生活会轻松一点。
解耦(Decoupling),解耦架构,每个组件通过明确的API和服务负载均衡器 与 其他组件隔离开,API 和负载均衡器把系统的各个部分彼此隔开。
通过 负载均衡器对组件进行解耦,可以很容易扩展成服务的程序规模,当你需要增加程序的规模(也就是提升容量)时,只需要增加实例数量,而不需要调整或重新配置系统的其他层。
当你需要扩展你的服务时,Kubernetes 的不可变(immutable)和声明式(declarative)特性使得扩展实现起来非常简单。
向上扩展服务只需要做一件事:修改配置文件中的一个数字。
也可以配置自动扩缩容(autoscaling),让 Kubernetes 自动替你完成这些事情。
扩展的前提是,集群里有足够的资源可以使用,可以及时扩展机器,创建一台同类型的新机器将它加入集群。
理想的团队规模是所谓的“两块披萨团队(tow-pizza team)”,大约6到8个人,这种规模通常带来良好的知识共享, 快速决策以及共同的目标感。
更大的团队往往会遇到一些问题,如:
解决这种矛盾常见方法,是构建 解耦的、面向服务的团队结构。每个小团队负责构建 一个单独的微服务,每个团队负责其服务的设计和交付,而这个服务会被其他小团队使用。
SLA(Service Level Agreement) 服务级别协议。
比如,应用开发者,只关心 Pod能启动 Service 能访问 负载均衡正常。
至于,节点坏了 磁盘坏了 VM重启,那是 Kubernetes 运维团队的事。
Kubernetes 是一个用于创建、部署和管理分布式应用程序的平台。
关于容器,希望你会使用Docker、了解Docker后再学习 Kubernetes。
容器映像是由一系列文件系统层构成的,每一层都继承并修改之前的层
.
└── container A: a base operating system only, such as Debian
└── container B: build upon #A, by adding Ruby v2.1.10
└── container C: build upon #A, by adding Golang v1.6. (continuing from above)
└── container B: build upon #A, by adding Ruby v2.1.10
└── container D: build upon #B, by adding Rails v4.2.6
└── container E: build upon #B, by adding Rails v3.2.x容器可分为两大类
Dockerfile 可用于自动创建 Docker 容器镜像。
打包一个Node.js 的 Express服务器
package.json
{
"name": "simple-node",
"version": "1.0.0",
"description": "A sample simple application for Kubernetes Up & Running",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"author": ""
}server.js
var express = require('express');
var app = express();
app.get('/', function (req, res) {
res.send('Hello World!');
});
app.listen(3000, function () {
console.log('Listening on port 3000!');
console.log(' http://localhost:3000');
});将其打包成 Docker 镜像,还需要创建两个文件 .dockerignore
和 Dockerfile
.dockerignore
node_modulesDockerfile
# Start from a Node.js 16 (LTS) image
FROM node:16
# Specify the directory inside the image in which all commands will run
WORKDIR /usr/src/app
# Copy package files and install dependencies
COPY package*.json ./
RUN npm install
RUN npm install express
# Copy all of the app files into the image
COPY . .
# The default command to run when starting the container
CMD [ "npm", "start" ]运行以下命令创建 simple-node Docker映像
docker build -t simple-node .运行一个基于 simple-node 映像的容器
docker run --rm -p 3000:3000 simple-node--rm 表示
容器停止后自动删除。-p 主机端口:容器端口 端口映射。
首先记住,被系统后续层删除的文件实际上仍然存在于镜像中,只是无法访问而已。
.
└── layer A: contains a large file named 'BigFile'
└── layer B: removes 'BigFile'
└── layer C: builds on B by adding a static binary另一个陷阱是 镜像缓存和构建,每次更改一个图层都会更改后面的图层,更改前面图层意味着需要重新构建、重新推送和重新删除。
.
└── layer A: contains a base OS
└── layer B: adds source code server.js
└── layer C: installs the 'node' package与
.
└── layer A: contains a base OS
└── layer B: installs the 'node' package
└── layer C: adds source code server.js后者更好,更改代码后 layer B 不用重新执行,docker有构建缓存。
安全没有捷径可走,不要构建包含密码的容器,不仅包括最终层,还包括镜像中的任何层。
由于容器镜像只专注于运行单个应用程序,因此最佳做法是尽量减少容器镜像中的文件,镜像中的每一个额外库都会为应用程序中出现的漏洞提供一个潜在的载体。
Docker引入了多阶段构建,通过多阶段构建,一个Docker文件实际上可以生成多个镜像,而不是生成一个镜像。
FROM golang:1.17-alpine
# Install Node and NPM
RUN apk update && apk upgrade && apk add --no-cache git nodejs bash npm
# Get dependencies for Go part of build
RUN go get -u github.com/jteeuwen/go-bindata/...
RUN go get github.com/tools/godep
RUN go get github.com/kubernetes-up-and-running/kuard
WORKDIR /go/src/github.com/kubernetes-up-and-running/kuard
# Copy all sources in
COPY . .
# This is a set of variables that the build script expects
ENV VERBOSE=0
ENV PKG=github.com/kubernetes-up-and-running/kuard
ENV ARCH=amd64
ENV VERSION=test
# Do the build. This script is part of incoming sources.
RUN build/build.sh
CMD [ "/go/bin/kuard" ]下面是一个多阶段 Dockerfile
# STAGE 1: Build
FROM golang:1.17-alpine AS build
# Install Node and NPM
RUN apk update && apk upgrade && apk add --no-cache git nodejs bash npm
# Get dependencies for Go part of build
RUN go get -u github.com/jteeuwen/go-bindata/...
RUN go get github.com/tools/godep
WORKDIR /go/src/github.com/kubernetes-up-and-running/kuard
# Copy all sources in
COPY . .
# This is a set of variables that the build script expects
ENV VERBOSE=0
ENV PKG=github.com/kubernetes-up-and-running/kuard
ENV ARCH=amd64
ENV VERSION=test
# Do the build. Script is part of incoming sources.
RUN build/build.sh
# STAGE 2: Deployment
FROM alpine
USER nobody:nobody
COPY --from=build /go/bin/kuard /kuard
CMD [ "/kuard" ]上面 Dockerfile 会生成两个镜像,
第一个是构建镜像,其中包含 Go编译器、React.js 工具链和程序源代码。
第二个是部署镜像,它只包含编译后的二进制文件。
使用多级构建来构建容器镜像,可以讲最终容器镜像的大小减少百兆字节,从而加快部署时间,一般来说部署延迟取决于网络性能。
Docker Hub 是公共仓库平台, 就像Github一样存代码,Docker Hub 用来存Docker镜像。
登录Docker Hub
docker login打tag
docker tag kuard gcr.io/kuar-demo/kuard-amd64:blue将镜像推到Docker Hub
docker push gcr.io/kuar-demo/kuard-amd64:blue| 部分 | 含义 |
|---|---|
gcr.io |
远程镜像仓库地址(Google Container Registry) |
kuar-demo |
项目 / namespace |
kuard-amd64 |
镜像名 |
blue |
tag(版本标签) |
本地镜像
kuard
│
│ docker tag
▼
gcr.io/kuar-demo/kuard-amd64:blue
│
│ docker push
▼
远程仓库 gcr.ioCRI API 由许多不同的程序实现,包括 Docker 构建的containerd-cri 和 Red Hat 贡献的cri-o 实现。安装 Docker 工具时,Docker 守护进程也会安装和使用containerd运行时。
从 Kubernetes 1.25 版开始,只有支持 CRI 的容器运行时才能与 Kubernetes 配合使用。 幸运的是,Kubernetes 托管服务提供商已为 Kubernetes 托管用户实现了几乎自动的过渡。
在 Kubernetes 中,容器通常由每个节点上名为 kubelet 的守护进程启动;
使用Docker命令工具更容易上手容器,Docker CLI工具可用于部署容器。
从 gcr.io/kuar-demo/kuard-amd64:blue 镜像部署容器
$ docker run -d --name kuard \
--publish 8080:8080 \
gcr.io/kuar-demo/kuard-amd64:blue-d 表示在后台运行,守护进程。
--publish 选项可简写为 -p。
--name kuard 给容器起了一个友好的名字。
Docker 通过公开 Linux 内核提供的底层 cgroup 技术,使应用程序能够使用更少的资源。
Kubernetes 同样使用这些功能来限制每个Pod使用的资源。
限制资源利用率,允许多个应用程序在同一硬件上共存,并确保公平使用。
例如限制 200MB 内存 和 1GB 交换空间,请在
docker run 命令中使用 --memory 和
--memory-swap 标志。
停止并删除当前名为 kuard 容器
$ docker stop kuard
$ docker rm kuard$ docker run -d --name kuard \
--publish 8080:8080 \
--memory 200m \
--memory-swap 1G \
gcr.io/kuar-demo/kuard-amd64:blue如果容器中的程序占用过多内存,就会被终止。
限制CPU的使用率 --cpu-shares。它表示
CPU调度权重,1024不是CPU数量,1024不是百分比,只是一个相对权重。
$ docker run -d --name kuard \
--publish 8080:8080 \
--memory 200m \
--memory-swap 1G \
--cpu-shares 1024 \
gcr.io/kuar-demo/kuard-amd64:blue完成构建镜像后,可以使用 docker rmi 命令删除镜像
docker rmi <tag-name>或
docker rmi <image-id>Docker 提供了一个名为 docker system prune
的工具,用于进行常规清理,它将移除所有停止的容器、所有未标记的镜像,
以及作为构建过程一部分缓存的所有未使用的镜像层。
应用程序容器为应用程序提供了一个简洁的抽象,当以 Docker 映像格式打包时,应用程序变得易于构建、部署和分发。容器还能隔离运行在同一台机器上的应用程序,有助于避免依赖冲突。
你需要一个能正常工作的 Kubernetes 集群。此时,大多数公有云中都有基于云的 Kubernetes 服务,只需几条命令行指令就能轻松创建一个集群。
minikube 工具提供了一种简单易用的方法,让本地 Kubernetes 集群在本地笔记本电脑或 台式机的虚拟机中启动运行。虽然这是一个不错的选择,但minikube 只能创建一个单节点集群,并不能完全展示完整 Kubernetes 集群的所有方面。
建议大家从基于 Cloud 的解决方案开始,除非它真的不适合自己的情况。
最近的一个替代方案是运行 Docker-in-Docker 集群,它可以在一台机器上启动一个多节点集群。
如 谷歌云平台 GCP 提供名为谷歌 Kubernetes 引擎(GKE)的托管 Kubernetes 即服务。
# 安装 gcloud 后 设置默认区域
$ gcloud config set compute/zone us-west1-a
# 创建一个集群
$ gcloud container clusters create kuar-cluster --num-nodes=3
# 获取群集的凭据
$ gcloud container clusters get-credentials kuar-clusterMicrosoft Azure 提供托管 Kubernetes 即服务,作为 Azure 容器服务的一部分。
亚马逊提供一种名为 “弹性 Kubernetes 服务(EKS)”的 Kubernetes 托管服务。
可以使用 minikube 安装一个简单的单节点集群。不推荐建议用kind。
https://minikube.sigs.k8s.io/docs/start
root@ser745692301841:/dev_dir# minikube version
minikube version: v1.38.1
commit: c93a4cb9311efc66b90d33ea03f75f2c4120e9b0启动集群
dev@ser745692301841:~$ minikube start
😄 minikube v1.38.1 on Ubuntu 24.04 (kvm/amd64)
✨ Automatically selected the docker driver
❗ Starting v1.39.0, minikube will default to "containerd" container runtime. See #21973 for more info.
🧯 The requested memory allocation of 3072MiB does not leave room for system overhead (total system memory: 3915MiB). You may face stability issues.
💡 Suggestion: Start minikube with less memory allocated: 'minikube start --memory=3072mb'
📌 Using Docker driver with root privileges
👍 Starting "minikube" primary control-plane node in "minikube" cluster
🚜 Pulling base image v0.0.50 ...
💾 Downloading Kubernetes v1.35.1 preload ...
> preloaded-images-k8s-v18-v1...: 910.66 KiB / 272.45 > preloaded-images-k8s-v18-v1...: 1.78 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 0 B [______________ > preloaded-images-k8s-v18-v1...: 2.61 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 1.60 KiB / 519.58 M > preloaded-images-k8s-v18-v1...: 3.17 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 65.75 KiB / 519.58 > preloaded-images-k8s-v18-v1...: 3.19 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 433.69 KiB / 519.58 > preloaded-images-k8s-v18-v1...: 3.66 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 929.64 KiB / 519.58 > preloaded-images-k8s-v18-v1...: 4.11 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 1.36 MiB / 519.58 M > preloaded-images-k8s-v18-v1...: 4.56 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 1.81 MiB / 519.58 M > preloaded-images-k8s-v18-v1...: 5.00 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 2.27 MiB / 519.58 M > preloaded-images-k8s-v18-v1...: 5.47 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 2.72 MiB / 519.58 M > preloaded-images-k8s-v18-v1...: 5.91 MiB / 272.45 M > gcr.io/k8s-minikube/kicbase...: 3.17 MiB / 519.58 M > > preloaded-images-k8s-v18-v1...: 57.00 MiB / 272.45 MiB 20.92% 2.15 MiB这将创建一个本地虚拟机,配置 Kubernetes,并创建指向该集群的本地kubectl 配置。 如前所述,这个集群只有一个节点,所以虽然它很有用,但与 Kubernetes 的大多数生产部署存在一些差异。
完成群集操作后,您可以使用以下命令停止虚拟机:
dev@ser745692301841:~$ minikube stop
✋ Stopping node "minikube" ...
🛑 Powering off "minikube" via SSH ...
🛑 1 node stopped.删除集群,可以运行
dev@ser745692301841:~$ minikube delete
🔥 Deleting "minikube" in docker ...
🔥 Deleting container "minikube" ...
🔥 Removing /home/dev/.minikube/machines/minikube ...
💀 Removed all traces of the "minikube" cluster.清理 minikube
dev@ser745692301841:/usr/local$ minikube delete --all --purge
🔥 Successfully deleted all profiles
💀 Successfully purged minikube directory located at - [/home/dev/.minikube]
dev@ser745692301841:/usr/local$最近开发的一种运行一个 Kubernetes 集群的不同方法,使用 Docker 容器模拟多个 Kubernetes 节点,而不是在虚拟机中运行一切。kind = Kubernetes IN Docker
Docker 容器 = Kubernetes节点
多个容器 = 一个 Kubernetes集群
你的电脑
│
├─ Docker
│ ├─ container (control-plane)
│ ├─ container (worker)
│ └─ container (worker)
│
└─ Kubernetes cluster也就是说你不用准备一堆虚拟机,就能在本地快速跑一个完整的 Kubernetes 集群。
安装docker,kind本质依赖Docker
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable docker
sudo systemctl start docker确认
docker version安装 kubectl,没有 kubectl,Kubernetes等于没装。
curl -LO https://dl.k8s.io/release/stable.txt
VERSION=$(cat stable.txt)
curl -LO https://dl.k8s.io/release/${VERSION}/bin/linux/amd64/kubectl
install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
kubectl version --client
root@ser745692301841:~# kubectl version --client
Client Version: v1.35.2
Kustomize Version: v5.7.1
root@ser745692301841:~#安装kind
curl -Lo ./kind https://kind.sigs.k8s.io/dl/latest/kind-linux-amd64
chmod +x kind
sudo mv kind /usr/local/bin/
root@ser745692301841:~# kind version
kind v0.32.0-alpha+c62c35f841826f go1.25.7 linux/amd64
root@ser745692301841:~#创建一个简单的集群
root@ser745692301841:~# kind create cluster
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.35.1) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! 👋检查,查看节点
root@ser745692301841:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 42s v1.35.1kind的每个节点其实都是Docker容器
root@ser745692301841:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cb81fdc1353b kindest/node:v1.35.1 "/usr/local/bin/entr…" About a minute ago Up About a minute 127.0.0.1:46063->6443/tcp kind-control-plane创建多节点集群
配置文件yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker创建
kind create cluster --config cluster.yamlkind删除集群
删除默认集群,默认名字叫kind
kind delete cluster删除指定名字的集群,如果创建的时候用了名字
# 创建时
kind create cluster --name mycluster
# 删除时
kind delete cluster --name mycluster验证删除了
root@ser745692301841:/dev_dir/avant# kind get clusters
No kind clusters found.kind 集群在一台机器里跑,但想让公网用户直接访问 Kubernetes 里的 Service。
问题在于一个残酷现实:kind 本质就是 Docker 容器里的 Kubernetes。所以 Service 的 IP(ClusterIP、甚至 NodeIP)基本都在 Docker 网络内部,外面的人根本看不到。
最简单粗暴 NodePort + 宿主机端口映射
Kubernetes 本身支持 Kubernetes 的 NodePort,但在 kind 里 Node 也是容器,所以还得再映射一层端口。
创建 NodePort Service
apiVersion: v1
kind: Service
metadata:
name: web
spec:
type: NodePort
selector:
app: web
ports:
- port: 80
targetPort: 80
nodePort: 30080访问路径会变成
宿主机IP:30080,但问题是,kind的nodePort没有暴露到宿主机还在Docker容器内。
创建kind集群时映射端口,建集群时写config
# kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30080
hostPort: 80
protocol: TCPkind create cluster --config kind-config.yaml标准点的方案Ingress
安装NGINX Ingress Controller
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/kind/deploy.yaml然后在 kind config里映射 80/443
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 80
hostPort: 80
- containerPort: 443
hostPort: 443之后外部访问流程
Internet
│
│ 80
▼
Host Machine
│
│ port mapping
▼
kind control-plane container
│
│ Ingress
▼
Service
│
▼
Podroot@ser745692301841:/dev_dir/k8s# kind delete cluster
Deleting cluster "kind" ...
Deleted nodes: ["kind-worker2" "kind-control-plane" "kind-worker"]
root@ser745692301841:/dev_dir/k8s# cat cluster.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 80
protocol: TCP
- role: worker
- role: worker
root@ser745692301841:/dev_dir/k8s# kind create cluster --config cluster.yaml
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.35.1) 🖼
✓ Preparing nodes 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Not sure what to do next? 😅 Check out https://kind.sigs.k8s.io/docs/user/quick-start/
root@ser745692301841:/dev_dir/k8s# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 30s v1.35.1
kind-worker NotReady <none> 16s v1.35.1
kind-worker2 NotReady <none> 15s v1.35.1
root@ser745692301841:/dev_dir/avant# cat avant-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: avant-deployment
spec:
replicas: 3
selector:
matchLabels:
app: avant
template:
metadata:
labels:
app: avant
spec:
volumes:
- name: avant-data
hostPath:
path: /var/www/html
containers:
- name: avant
image: gaowanlu/avant:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 20023
name: http
protocol: TCP
resources:
requests:
cpu: "1000m"
memory: "128Mi"
limits:
cpu: "2000m"
memory: "512Mi"
volumeMounts:
- name: avant-data
mountPath: "/avant_static"
livenessProbe:
httpGet:
path: /
port: 20023
initialDelaySeconds: 120
timeoutSeconds: 10
periodSeconds: 30
failureThreshold: 5
readinessProbe:
httpGet:
path: /
port: 20023
initialDelaySeconds: 120
timeoutSeconds: 10
periodSeconds: 30
failureThreshold: 5
---
apiVersion: v1
kind: Service
metadata:
name: avant-service
spec:
type: NodePort
externalTrafficPolicy: Cluster
selector:
app: avant
ports:
- protocol: TCP
port: 80
targetPort: 20023
nodePort: 30000
root@ser745692301841:/dev_dir/avant# kubectl apply -f avant-deployment.yaml
deployment.apps/avant-deployment created
service/avant-service created
# 公网能访问kind搭建的k8s集群的service了
root@ser745692301841:/dev_dir/avant# curl http://0.0.0.0:80
hello worldKubernetes的官方客户端是kubectl,一个与Kubernetes API交互的命令行工具。
kubectl 可以管理大多数 Kubernetes 对象,如 Pod、ReplicaSets、Services,也可以用于探索和验证集群的整体健康状况。
检查集群状态
root@ser745692301841:/dev_dir/note# kubectl version
Client Version: v1.35.2
Kustomize Version: v5.7.1
Server Version: v1.35.1可以对集群进行简单的诊断,这是验证集群总体健康状况的好方法
root@ser745692301841:/dev_dir/note# kubectl get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok 这里可以看到组成 Kubernetes 集群的各个组件。
controller-manager
负责运行调节集群行为的各种控制器,如确保服务的所有副本都可以用且健康。scheduler 负责将不同的Pod放到集群中的不同节点上。etcd
服务器是集群的存储设备,所有API对象都存储在这里。可以列出集群中的所有节点
root@ser745692301841:/dev_dir/note# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 12m v1.35.1这是一个运行了12分钟的1节点集群。在 Kubernetes中,节点被分为
Kubernetes一般不会将工作调度到 control-plane节点上,以确保用户工作负载不会损害集群的整体运行。
可以使用 kubectl describe 命令获取有关特定节点的更多信息,如 kube1
root@ser745692301841:/dev_dir/note# kubectl describe nodes kind-control-plane
Name: kind-control-plane
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kind-control-plane
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
Annotations: node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Wed, 11 Mar 2026 11:41:11 +0000
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: kind-control-plane
AcquireTime: <unset>
RenewTime: Wed, 11 Mar 2026 11:56:34 +0000
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Wed, 11 Mar 2026 11:52:59 +0000 Wed, 11 Mar 2026 11:41:08 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Wed, 11 Mar 2026 11:52:59 +0000 Wed, 11 Mar 2026 11:41:08 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Wed, 11 Mar 2026 11:52:59 +0000 Wed, 11 Mar 2026 11:41:08 +0000 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 11 Mar 2026 11:52:59 +0000 Wed, 11 Mar 2026 11:41:35 +0000 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.18.0.2
Hostname: kind-control-plane
Capacity:
cpu: 4
ephemeral-storage: 50620216Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 4009176Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 50620216Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 4009176Ki
pods: 110
System Info:
Machine ID: a571291cce3a40dd97170c3d6b97b59c
System UUID: a7abdd46-57c6-413f-be98-f4b43b810536
Boot ID: 6019958d-3d9a-47be-bbb8-b9efb77d3bcb
Kernel Version: 6.8.0-90-generic
OS Image: Debian GNU/Linux 13 (trixie)
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://2.2.1
Kubelet Version: v1.35.1
Kube-Proxy Version:
PodCIDR: 10.244.0.0/24
PodCIDRs: 10.244.0.0/24
ProviderID: kind://docker/kind/kind-control-plane
Non-terminated Pods: (9 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system coredns-7d764666f9-9ct7w 100m (2%) 0 (0%) 70Mi (1%) 170Mi (4%) 15m
kube-system coredns-7d764666f9-hr26r 100m (2%) 0 (0%) 70Mi (1%) 170Mi (4%) 15m
kube-system etcd-kind-control-plane 100m (2%) 0 (0%) 100Mi (2%) 0 (0%) 15m
kube-system kindnet-5x9l9 100m (2%) 100m (2%) 50Mi (1%) 50Mi (1%) 15m
kube-system kube-apiserver-kind-control-plane 250m (6%) 0 (0%) 0 (0%) 0 (0%) 15m
kube-system kube-controller-manager-kind-control-plane 200m (5%) 0 (0%) 0 (0%) 0 (0%) 15m
kube-system kube-proxy-zxp5z 0 (0%) 0 (0%) 0 (0%) 0 (0%) 15m
kube-system kube-scheduler-kind-control-plane 100m (2%) 0 (0%) 0 (0%) 0 (0%) 15m
local-path-storage local-path-provisioner-84669cbbb8-mw7l8 0 (0%) 0 (0%) 0 (0%) 0 (0%) 15m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 950m (23%) 100m (2%)
memory 290Mi (7%) 390Mi (9%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal RegisteredNode 15m node-controller Node kind-control-plane event: Registered Node kind-control-plane in Controller
root@ser745692301841:/dev_dir/note# 其中 Name、Role、Labels 可以看到,节点正在什么处理器上运行Linux操作系统。
Conditions 可以看到运行信息。Capacity 状态现实节点磁盘和内存空间信息,System Info 显示 Docker版本、Kubernetes和Linux内核版本等等。
Non-terminated Pods 当前在该节点上运行的Pod的信息。
可以看到节点上的Pod(如,为集群提供DNS服务的 kube-dns Pod)、每个 Pod 向节点请求的 CPU 和内存,以及请求的总资源。
Kubernetes 会同时跟踪在机器上运行的每个 Pod 的资源请求和上限。
Pod 请求的资源保证存在于节点上,而 Pod 的限制则是 Pod 可以消耗的给定资源的最大数量。Pod 的限制可能高于其请求,在这种情况下,额外的资源会尽力提供。不保证节点上一定有这些资源。
组成Kubernetes集群的许多组件实际上是使用Kubernetes本身部署的。所有这些组件都在
kube-system 命名空间中运行。
Kubernetes代理负责将网站流量路由到 Kubernetes
集群中的负载平衡服务。代理存在于集群中的每个节点上, Kubernetes
有一个名为 DaemonSet 的API对象。
查看 kube-system 命令空间里的 kube-proxy
DaemonSet 装。
root@ser745692301841:/dev_dir/note# kubectl get daemonSets --namespace=kube-system kube-proxy
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 31mKubernetes还运行了一个DNS服务器,为集群中定义的服务提供命名和发现功能。
DNS 服务器也作为集群上的复制服务运行。根据集群的规模,您可能会看到一个或多个 DNS 服务器在集群中运行。DNS 服务作为 Kubernetes 部署运行,由 Kubernetes 来管理这些副本(这也可能被命名为 或其他变体):coredns
root@ser745692301841:/dev_dir/note# kubectl get deployments --namespace=kube-system coredns
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 44m
root@ser745692301841:/dev_dir/note# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 44m这表明集群的DNS服务地址为
10.96.0.10,如果登录集群中的容器,就会发现该地址已被填入容器
/etc/resolv.conf 文件中。
大多数云提供商都会把可视化集成到其云的图形用户界面。集群仪表盘。还可以用 Visual Studio Code 等开发环境的扩展,查看集群的状态。
此时已经建立了运行一个(或三个)Kubernetes集群,使用了一些命令探索创建的集群。下面将会学习掌握 kubectl 工具。
kubectl 命令行工具,可以用它来创建对象并于Kubernetes API交互。
Kubernetes 使用命名空间来组织集群中的对象。
默认情况下,kubectl 命令行工具与 default 命名空间交互。可以传递
--namespace 标志 如 --namespace=mystuff 引用
mystuff 命名空间中的对象。也可以使用 -n 缩写标记。
与所有命名空间交互,可以传递 --all-namespace 标志。
kubectl 会把集群连接信息、用户认证信息、上下文等内容都存到一个文件里。
说人话,context 上下文 本质就是一条配置,告诉 kubectl三件事,连接哪个集群?用哪个用户身份认证?默认使用哪个 namespace?
root@ser745692301841:/dev_dir/note# cat $HOME/.kube/config里面主要内容包含三类
context = cluster + user + namespace创建一个新的 context,一个叫 my-context 的 context 默认namespace 设为 mystuff。这只是写进配置文件,还没有启用。
root@ser745692301841:/dev_dir/note# kubectl config set-context my-context --namespace=mystuff
Context "my-context" created.启用这个 context
root@ser745692301841:/dev_dir/note# kubectl config use-context my-context
Switched to context "my-context".
root@ser745692301841:/dev_dir/note# 从这一刻,所有 kubectl 命名默认都会在 mystuff namespace 里执行。
例如
kubectl get pods
# 实际等价于
kubectl get pods -n mystuff
# 查看当前context
root@ser745692301841:/dev_dir/note# kubectl config current-context
my-context
# 查看所有context
root@ser745692301841:/dev_dir/note# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
kind-kind kind-kind kind-kind
* my-context mystuff
# 切换context
root@ser745692301841:/dev_dir/note# kubectl config use-context kind-kind
Switched to context "kind-kind".
# 删除context
root@ser745692301841:/dev_dir/note# kubectl config delete-context my-context
deleted context my-context from /root/.kube/config
# 查看所有context
root@ser745692301841:/dev_dir/note# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kind-kind kind-kind kind-kind kubectl 本质是 Kubernetes API 的客户端。
kubectl
↓
HTTP 请求
↓
Kubernetes API Server
↓
REST API 对象在 Kubernetes 中,所有内容都被标识为 RESTful 资源。这些资源被称为 Kubernetes 对象(Kubernetes Objects)。
每个 Kubernetes 对象都有一个唯一的HTTP路径,如
https://your-k8s.com/api/v1/namespaces/default/pods/my-pod这个URL表示,namespace是default,资源类型为 pods,pod名称为
my-pod, 也就是这个地址对应 default 命名空间里的
my-pod Pod对象。
kubectl 命名其实就是在向这些URL发送HTTP请求,从而获取或操作Kubernetes对象。
查看 Kubernetes 对象
最基础的命令是
kubectl get <resource-name>
# 例如
root@ser745692301841:/dev_dir/note# kubectl get pods
No resources found in default namespace.
# 如果想要查看具体对象
kubectl get <resource-name> <obj-name>
# 例如
kubectl get pods my-pod输出格式
默认情况,kubectl 会使用可读格式显示数据,为了让每个对象只占一行,它会隐藏很多字段。
kubectl get pods -o wide其中 -o wide 会显示更多字段,例如 Pod
IP、Node、Image。
查看完整对象
如果想看完整数据结构,可以输出
# JSON
kubectl get pod my-pod -o json
# YAML
kubectl get pod my-pod -o yaml去掉表头
有时需要配合Linux管道,比如
kubectl get pods | awk ...这时表头反而是干扰。
可以
--no-headers
# 例如
kubectl get pods --no-headers提取特定字段JSONPath
有时只想拿对象里的某个字段,例如 Pod IP
kubectl支持JSONPath查询语言
kubectl get pods my-pod -o jsonpath --template={.status.podIP}
10.244.1.12
# 意思是 .status.podID 这个字段同时查看多种资源
可以用 逗号分隔,同时列出 Pods、Services
root@ser745692301841:/dev_dir/note# kubectl get pods,services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19h查看对象详细信息
想看更详细的说明,可以用
kubectl describe <resource-name> <obj-name>
# 例如
root@ser745692301841:/dev_dir/note# kubectl describe services kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver
provider=kubernetes
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.0.1
IPs: 10.96.0.1
Port: https 443/TCP
TargetPort: 6443/TCP
Endpoints: 172.18.0.2:6443
Session Affinity: None
Internal Traffic Policy: Cluster
Events: <none>查看字段说明,如果不知道某个资源有哪些字段,可以用
kubectl explain pods
# 例如
kubectl explain pods.spec实时监控资源变化
有时需要持续观察资源变化,如:Pod重启、Deployment rollout、Job完成
可以用
--watch
# 例子
root@ser745692301841:/dev_dir/note# kubectl get services --watch
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19h80%的排错都在用
kubectl get
kubectl describe
kubectl logs回到现实,所有东西其实就是一堆 JSON、YAML文件配置,Kubernetes也没例外,它把这些文件叫做 Kubernetes 对象(Objects)
Kubernetes对象的表示方式
在Kubernetes API中,对象通常用两种格式表示:
这些文件可能来自两种地方:
Kubernetes的世界基本就是:写 YAML → 发给 API Server → 服务器保存状态
创建对象
例如有一个 obj.yaml,创建对象的命令
apiVersion: v1
kind: Pod
metadata:
name: mypod创建对象的命令,不要慌 我们还没学yaml怎么写,有哪些字段,先直到 kubectl 的大致命令就好
root@ser745692301841:/dev_dir/k8s# kubectl apply -f obj.yaml
The Pod "mypod" is invalid: spec.containers: Required value其中 -f 表示file,
不需要指定资源类型,因为YAML里面已经写了.
更新对象
修改 obj.yaml 后,再执行一次
kubectl apply -f obj.yamlapply的行为是:只更新有变化的部分
如果对象:
预览 apply(dry-run)
如果你不确定 apply 会做什么,可以先预览:
kubectl apply -f obj.yaml --dry-run=client效果:不会真的发送到服务器,只会在终端显示结果,等于 Kubernetes的 “试运行模式”
交互式编辑对象
如果你不想修改本地YAML,可以直接编辑集群里的对象
kubectl edit <resource> <name>
# 例如
kubectl edit deployment nginx流程:
查看apply历史
kubectl apply 会把最后一次配置记录在对象的 annotation 里。
| 命令 | 作用 |
|---|---|
view-last-applied |
查看最后一次 apply |
edit-last-applied |
编辑最后一次 apply |
set-last-applied |
手动设置 |
# 示例
kubectl apply -f myobj.yaml view-last-applied
# 会显示
kubectl.kubernetes.io/last-applied-configuration
# 里面就是上次的YAML删除对象
kubectl delete -f obj.yaml不会提示确认,命令执行后对象就没了,人们经常在生产环境打出这个命令后瞬间沉默三秒。
通过资源名删除
kubectl delete <resource> <name>例如
# 删除 Pod
kubectl delete pod nginx
# 删除 Deployment
kubectl delete deployment web用 kubectl 的人,基本天天用的就是这几个
kubectl get
kubectl describe
kubectl apply
kubectl delete
kubectl logsLabel(标签) 和 Annotation(注解) 本质上都是给 Kubernetes 对象打的“标记”。
例如,给一个叫 bar 的Pod添加一个 color=red 的标签。
kubectl label pods bar color=red
# annotation 的语法完全一样默认情况下,kubectl label 和
kubectl annotate 不会覆盖已存在的标签。非要改的话
kubectl label pods bar color=blue --overwrite删除Label
kubectl label pods bar color-
# 意思是 删除 Pod bar上的color标签Kubernetes提供了一些 kubectl 命令,用来查看日志、进入容器、复制文件、端口转发、查看事件和资源使用情况。基本所有线上问题都离不开这些命令。
查看容器日志
查看某个Pod中容器的日志
kubectl logs <pod-name>例如
kubectl logs my-pod如果一个Pod里有多个 container,需要指定容器
kubectl logs <pod-name> -c <container-name>
# 例如
kubectl logs my-pod -c nginx实时查看日志,默认只打印当前日志然后退出,如果想 持续输出日志
kubectl logs -f <pod-name>在容器中执行命令
作用:进入运行中的容器执行命令
kubectl exec -it <pod-name> -- bash| 参数 | 作用 |
|---|---|
-i |
保持 stdin 打开 |
-t |
分配终端 |
-- |
后面是容器里的命令 |
示例
kubectl exec -it my-pod -- bash
# 如果容器没有bash,很多alpine镜像没有
kubectl exec -it my-pod -- shattach到容器进程
kubectl attach -it <pod-name>它的作用是:连接到容器当前运行的进程,类似
docker attach| 命令 | 作用 |
|---|---|
| logs | 只看输出 |
| attach | 可以输入 |
前提:容器程序必须读取 stdin,很多web服务用不上这个。
复制文件
复制文件(Pod ↔︎ 本地)。
从容器复制文件到本地:
kubectl cp <pod-name>:</path/to/remote/file> </path/to/local/file>
# 例子
kubectl cp my-pod:/tmp/test.log ./test.log从本地复制到容器
kubectl cp ./text.log my-pod:/tmp/test.log支持 目录复制
Pod端口转发
kubectl port-forward <pod-name> 8080:80意思是,本地 8080 转发到 Pod 80,访问 localhost:8080
就等于访问 Pod:80。
Service端口转发
kubectl port-forward service/<service-name> 8080:80只会转发到一个Pod,不会走 Service 的负载均衡。
查看Kubernetes事件
查看最新10个事件,比如 Pod创建、Pod调度、Pod启动失败、镜像拉取失败。
kubectl get events实时查看事件,持续输出
kubectl get events --watch查看所有 namespace:
kubectl get events -A查看资源使用情况
查看 节点资源,输出 CPU 使用量、内存使用量、使用百分比。
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node-1 300m 15% 1.2Gi 40%查看Pod资源
# 默认只显示当前 namespace
kubectl top pods
# 查看所有
kubectl top pods --all-namespaceskubectl top 能不能用取决于
metrics-server,是否安装,没装会报错
root@ser745692301841:/dev_dir/k8s# kubectl top nodes
error: Metrics API not available
root@ser745692301841:/dev_dir/k8s# kubectl top pods
error: Metrics API not available大多数 云 Kubernetes 都自带,EKS、GKE、AKS,自己搭的集群如 minikube、kubeadm 可能都要手动安装。
准备修服务器时,先把活儿挪走再动刀子。 不然容器直接被你干掉,业务就跟着躺平。
kubectl也能管理集群节点
kubectl 不只是用来看 Pod、Service 这些对象,它还可以 管理整个集群的节点(Node)。最常见的两个
场景:服务器硬件维修、系统升级、Kubernetes 节点维护、机器要重启
cordon:给节点挂个 暂停营业的牌子
kubectl cordon <node-name>禁止新的Pod被调度到这个节点上,已经在运行的Pod不会动,只会以后不让新Pod来。像饭店挂个牌子,今日不接新客、但店里正在吃饭的人你总不能赶出去。
drain:把这个节点的 Pod 全部赶走,把节点上所有 Pod 都迁移走。
kubectl drain <node-name>Kubernetes 先删除这些 Pod、然后调度器会在其他节点重新创建。有些Pod不让删比如 DaemonSet、没控制器的裸Pod,所以通常会这么写:
kubectl drain <node-name> --ignore-daemonsets修完之后:uncordon,把停止营业牌子去掉,调度器可以像这个节点分配Pod
kubectl uncordon node1kubectl 支持 Shell 自动补全。
例如
kubectl get po<Tab>
# 会自动补全成
kubectl get pods如果资源很多,Tab还能列出候选项。
apt-get install bash-completion临时启用kubectl自动补全
source <(kubectl completion bash)效果:当前terminal有自动补全,关闭terminal就没了。
| 方式 | 工具 | 特点 |
|---|---|---|
| 命令行 | kubectl | 最标准、最强大 |
| IDE 插件 | VS Code / IntelliJ / Eclipse | 开发体验好 |
| 图形界面 | Rancher / Headlamp / 云平台控制台 | 可视化管理 |
kubectl 是一个非常强大的命令行工具,用来管理你在 Kubernetes 集群中的 应用程序和资源。
上面只是展示了 kubectl 的一些常见用法,实际上还有很多很多其他功能。
kubectl help例如
kubectl help get
kubectl help apply
kubectl help logs| 命令 | 作用 |
|---|---|
kubectl help |
查看所有命令 |
kubectl help get |
查看某个命令 |
kubectl get --help |
另一种查看方式 |
容器化应用程序的实际部署中,通常希望多个应用程序集中到一个原子单元中,并调度到 一台机器上。
例如下面的 Pod,其中包含一个为网络请求提供服务的容器和一个将文件系统与远程Git仓库同步的容器。
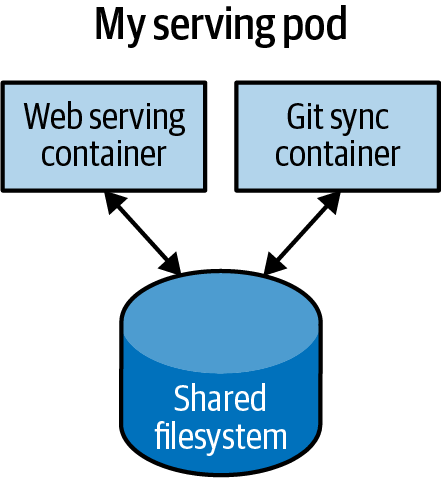
这两个容器是相当共生的,在一台机器上调度网络服务器, 在另一台机器上调度Git同步器是没有意义的。Kubernetes 将多个容器组合成一个原子单元,称为Pod。
Pod是在同一执行环境中运行的应用程序容器和卷的集合。
Pod 是 Kubernetes 集群中最小的可部署工件,而不是容器。这意味着 Pod 中的所有容器始终位于同一台机器上。
Pod 中的每个容器都在自己的 cgroup 中运行,但它们共享一些 Linux 命名空间。
同Pod中运行的应用程序
不同Pod中的应用程序是相互隔离的,它们拥有不同的IP地址、主机名等。
在同一节点上运行的不同Pod中的容器,也可能在不同的服务器上。
当人们开始使用Kubernetes时,最常见的问题之一是:
“我应该把什么放进一个Pod里?”
共生关系
例如 WorldPress 和 数据库 并不是共生关系,分别放在不同机器上,它们通过网络连接依然可以工作,把它们硬塞到一个Pod并没有必要。
扩缩容策略
WordPress和MySQL的扩展方式不同
WordPress基本是无状态,可以增加Pod来扩容。MySQL是有状态且扩展很复杂,通常做法是增加单个数据库实例的资源CPU和内存,或者做复杂的数据库集群。
把它们放进一个Pod里,显然是非常扯淡的。
设计Pod的正确思考方式
应该问自己:如果这些容器被调度到不同机器上,它们还能正常工作吗?
简单规则,“必须在同一台机器上才能正常工作的容器,才应该放进同一个 Pod”
Pod是通过 Pod Manifest来描述的,本质上就是 Kubernetes API对象的一种文本文件表示。
Kubernetes强调 声明式配置 思想,把系统“期望达到的状态”写在一个配置文件里,然后把这个配置提交给某个服务,由这个服务负责采取各种操作,让系统最终达到这个期望状态。
Kubernetes调度器会尽量把同一个应用的Pod分散到不同机器上,从而提高系统在发生故障时的可靠性。
一旦Pod被调度到某个节点,它不会自动迁移到别的节点,如果需要换节点必须 销毁Pod、重新调度创建新Pod。
想运行多个Pod实例,推荐使用 ReplicaSet,来管理多个Pod副本。
总之,写YAML(描述你想要什么),Kubernetes自动帮你实现,如果坏了它会自己“修”。
创建Pod最简单的方法,是使用 命令式 的 kubectl run
命令。
例如
root@ser745692301841:/dev_dir/note# kubectl run kuard \
--image=nginx
pod/kuard created
root@ser745692301841:/dev_dir/note# kubectl get pods
NAME READY STATUS RESTARTS AGE
kuard 0/1 ContainerCreating 0 11s
root@ser745692301841:/dev_dir/note# kubectl get pods
NAME READY STATUS RESTARTS AGE
kuard 1/1 Running 0 64s
# 删除Pod
root@ser745692301841:/dev_dir/note# kubectl delete pod kuard
pod "kuard" deleted from default namespace
root@ser745692301841:/dev_dir/note# kubectl get pods
No resources found in default namespace.可以使用YAML和JSON来编写Pod的清单文件,更推荐YAML。
Pod配置通常包含几个关键字段和属性
例如 docker 部署的
$ docker run -d --name kuard \
--publish 8080:8080 \
gcr.io/kuar-demo/kuard-amd64:blue写一个 Pod 配置文件,kuard-pod.yaml,然后使用 kubectl 命令把该配置加载到 Kubernetes 集群中。
kuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- name: kuard
image: gcr.io/kuar-demo/kuard-amd64:blue
ports:
- containerPort: 8080
name: http
protocol: TCP显示几乎没人直接用Pod,因为Pod 不会自动重启、不会自动扩容、不会滚动升级,真实环境一般用 Deployment 来管理Pod。
可以用pod的yaml启动一个运行kuard的Pod,使用 kubectl apply 命令
$ kubectl apply -f kuard-pod.yaml这个 Pod 配置文件 会被提交到 Kubernetes API Server,系统把这个Pod调度到集群中 的某个健康节点(node)上运行。在该节点上,kubelet 守护进程 会持续监控这个 Pod 的运行状态。
Nginx Pod示例
nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
protocol: TCP创建一个 nginx-pod Pod实例
root@ser745692301841:/dev_dir/k8s# kubectl apply -f nginx-pod.yaml
pod/nginx-pod created查看运行状态
root@ser745692301841:/dev_dir/k8s# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 34s
root@ser745692301841:/dev_dir/k8s# kubectl delete pod nginx-pod
pod "nginx-pod" deleted from default namespace你会发现不能访问,Pod默认不能直接从外部访问,进行端口转发
root@ser745692301841:/dev_dir/k8s# kubectl port-forward pod/nginx-pod 7777:80
Forwarding from 127.0.0.1:7777 -> 80
Forwarding from [::1]:7777 -> 80
root@ser745692301841:/dev_dir/k8s# curl http://127.0.0.1:20030/root@ser745692301841:/dev_dir/k8s# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 34s现在有了一个正在运行的Pod,可以看到Pod的名称 nginx-pod,是在 yaml
metadata.name 起的名字。已就绪容器的数量
1/1,输出还显示了Pod的状态、重启次数、Pod年龄。
root@ser745692301841:/dev_dir/k8s# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-pod 1/1 Running 0 26s 10.244.0.9 kind-control-plane <none> <none>可以选择以 JSON格式 和 YAML格式 输出结果。
kubectl get pods -o json
kubectl get pods -o yaml有更加详细的信息可以使用 kubectl describe
root@ser745692301841:/dev_dir/k8s# kubectl describe pods nginx-pod
Name: nginx-pod
Namespace: default
Priority: 0
Service Account: default
Node: kind-control-plane/172.18.0.2
Start Time: Thu, 12 Mar 2026 14:26:57 +0000
Labels: app=nginx
Annotations: <none>
Status: Running
IP: 10.244.0.9
IPs:
IP: 10.244.0.9
Containers:
nginx:
Container ID: containerd://c1fe99e2feff8ceb8c2c1e32f5af48d9e477735ba3572bae9d8a6de066c36288
Image: nginx:latest
Image ID: docker.io/library/nginx@sha256:bc45d248c4e1d1709321de61566eb2b64d4f0e32765239d66573666be7f13349
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 12 Mar 2026 14:26:58 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-96s25 (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-96s25:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
Optional: false
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 5m38s default-scheduler Successfully assigned default/nginx-pod to kind-control-plane
Normal Pulling 5m38s kubelet spec.containers{nginx}: Pulling image "nginx:latest"
Normal Pulled 5m37s kubelet spec.containers{nginx}: Successfully pulled image "nginx:latest" in 441ms (441ms including waiting). Image size: 62960551 bytes.
Normal Created 5m37s kubelet spec.containers{nginx}: Container created
Normal Started 5m37s kubelet spec.containers{nginx}: Container started
root@ser745692301841:/dev_dir/k8s# 顶部是Pod的基本信息、Containers部分有Pod中运行的容器信息、还有一些与Pod相关的事件, 何时拉镜像、是否何时因健康检查失败而必须重新启动Pod。
root@ser745692301841:/dev_dir/k8s# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 25m
root@ser745692301841:/dev_dir/k8s# kubectl delete pods/nginx-pod
pod "nginx-pod" deleted from default namespace当删除Pod时,Pod不会立即被杀死,如果运行
kubectl get pods 可能会看到 Pod 处于 Terminating 状态。所有
Pod 都有一个终止宽限期,默认为30秒。
当Pod过渡到 Terminating 时,不再接收新请求。删除 Pod 时,存储在与 Pod 相关联的容器中的任何数据也将被删除。 如果要在 Pod 的多个实例中持久保存数据,则需要使用 PersistentVolumes。
root@ser745692301841:/dev_dir/k8s# kubectl logs nginx-pod
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2026/03/12 14:55:41 [notice] 1#1: using the "epoll" event method
2026/03/12 14:55:41 [notice] 1#1: nginx/1.29.6
2026/03/12 14:55:41 [notice] 1#1: built by gcc 14.2.0 (Debian 14.2.0-19)
2026/03/12 14:55:41 [notice] 1#1: OS: Linux 6.8.0-90-generic
2026/03/12 14:55:41 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1073741816:1073741816
2026/03/12 14:55:41 [notice] 1#1: start worker processes
2026/03/12 14:55:41 [notice] 1#1: start worker process 36
2026/03/12 14:55:41 [notice] 1#1: start worker process 37
2026/03/12 14:55:41 [notice] 1#1: start worker process 38
2026/03/12 14:55:41 [notice] 1#1: start worker process 39使用 -f 标志可以使日志流持续不断
root@ser745692301841:/dev_dir/k8s# kubectl logs nginx-pod -f但企业生产环境,一般都用 日志聚合服务,比如 Fluentd 和 Elasticsearch,以及众多云日志提供商。 这些日志服务容量大,可存储更长时间,提供丰富的日志搜索和过滤功能。许多服务还能将 多个Pod 的日志聚合到一个 视图中。
有时仅查看日志是不够的,需要直接在容器的运行环境中执行命令。
root@ser745692301841:/dev_dir/k8s# kubectl exec nginx-pod -- date
Thu Mar 12 15:05:57 UTC 2026如果希望获得一个交互式终端会话,可以加上 -it 参数
root@ser745692301841:/dev_dir/k8s# kubectl exec -it nginx-pod -- sh
# ls
bin docker-entrypoint.d home media proc root srv usr
boot docker-entrypoint.sh lib mnt product_name run sys var
dev etc lib64 opt product_uuid sbin tmp向容器中复制文件其实是一种反模式,更推荐的做法是把容器内存当作不可变的。
kubectl cp 示例
# 复制文件到Pod
kubectl cp local.txt mypod:/app/local.txt
# 从Pod复制出来
kubectl cp mypod:/app/log.txt ./log.txtKubernetes中以容器形式运行应用时,系统会通过进程健康检查自动帮你保持应用存活。
仅检查进程是否存在是不够的,只能检查进程是否存活但程序逻辑有问题也是不健康的,Kubernetes引入了 应用存活检查,会执行一些与应用相关的逻辑,例如
确认,应用不仅还在运行,而且确实能够正常工作。
| 检查类型 | Kubernetes 做什么 | 问题 |
|---|---|---|
| 进程检查 | 只看进程在不在 | 程序卡死也看不出来 |
| Liveness 检查 | 真正访问应用功能 | 能判断应用是否真的还能用 |
存活探针是按容器定义的,Liveness Probe(存活探针),Pod里的每个容器都会单独进行健康检查。
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
livenessProbe:
httpGet:
path: /healthy
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3
ports:
- containerPort: 8080
name: http
protocol: TCP上面yaml内容解释,会对kuard容器的8080端口的 /healthy
接口发送HTTP GET请求。
存活探针失败默认会重启,但实际行为由 Pod 的 restartPolicy 控制,有3种策略
存活检查 liveness 和 就绪检查 readiness 是两个不同概念。
逻辑换为人话:一个负责生死,一个负责接活。
当一个Pod启动时,startup probe 会 在任何其他探针运行之前先执行。
startup probe 会持续执行检查,直到发生以下两种情况之一:
| 阶段 | 负责的探针 | 作用 |
|---|---|---|
| 容器刚启动 | Startup Probe | 判断应用是否完成启动 |
| 启动完成后 | Liveness Probe | 判断应用是否仍然活着 |
说人话:
有效能防止应用还没启动就把它当成死人重启。
出来HTTP检查之外,还支持tcpSocket健康检查,还允许使用exec探针,常见三种套路
大多数人开始使用容器和Kubernetes这样的编排系统,是因为它们在镜像打包和可靠部署方面 带来了巨大的进度。还能提高集群计算节点的整体利用率。
利用率的定义
实际正在使用的资源量 / 已购买的资源总量
Kubernetes的两种资源配置
Resource Requests 资源请求、Resource Limits 资源上限。
资源请求:运行应用所需要的最小资源量,调度器根据这个值决定Pod可以被调度到哪台节点上, 节点是否有足够资源运行这个Pod。requests = 调度保证。
资源上线:应用程序最多可以使用多少资源,如果容器尝试超过这个值的资源,CPU会被限制,内存 可能会被OOM kill。limits = 运行时上限。
Kubernetes资源单位
直接数字 如
12345,millicores(毫核)100m。
| CPU 表达 | 含义 |
|---|---|
1 |
1 个 CPU 核 |
500m |
0.5 CPU |
100m |
0.1 CPU |
内存单位的区别,Kubernetes种有两种不同的单位体系
| 单位 | 类型 | 含义 |
|---|---|---|
| MB / GB / PB | 二进制 | 1 MB = 1024 KB |
| MiB / GiB / PiB | 十进制 | 1 MiB = 1000 KiB |
400m = 0.4MB 而不是 400MB。
当Pod为器容器请求资源时,Kubernetes会保证这些资源在节点上是可用的。
最常见资源:CPU、Memory、GPU。
例如,如果希望 kuard 容器运行在,至少0.5个CPU,128MB内存的机器上
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
resources:
requests:
cpu: "500m"
memory: "128Mi"
ports:
- containerPort: 8080
name: http
protocol: TCP| 配置 | 含义 |
|---|---|
cpu: 500m |
请求 0.5 个 CPU |
memory: 128Mi |
请求 128MB 内存 |
资源是按Container申请的
资源请求是 按容器计算的,不是按Pod。
Pod资源 = 所有容器资源 requests 之和Kubernetes调度器会根据 requests 来决定Pod放在哪个节点。调度规则:节点上所有Pod的 requests总和不能超过节点容量。requests是Kubernetes的调度依据。
requests是最小值,不是最大值。最少保证。
CPU Requests的实现原理,在Linux中通过 cpu-shares 机制实现,本质是按权重公平分配CPU。
Memory Requests的重要区别,内存和CPU有一个关键不同点,CPU可以随时减少,而内存不能随便拿走。 当系统内存不足OOM时,kubelet会 终止那些内存使用大于request的容器,然后自动重启容器。
一句话 “requests = Kubernetes保证给你的最少资源”。生产环境一定要同时设置 requests和limits。
可以通过资源限制设置Pod资源使用的最大值。
kuard-pod-reslim.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "256Mi"
ports:
- containerPort: 8080
name: http
protocol: TCPCPU会限制,内存超了会OOM。
访问持久磁盘存储是健康应用的重要组成部分。Kubernetes 就是这样的持久性存储模型。
先看配置 kuard-pod-vol.yaml,创建一个叫
kuard-data的volume,它映射的是宿主机目录 /var/lib/kuard
宿主机
/var/lib/kuard
│
▼
容器
/dataapiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
volumes:
- name: "kuard-data"
hostPath:
path: "/var/lib/kuard"
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
volumeMounts:
- mountPath: "/data"
name: "kuard-data"
ports:
- containerPort: 8080
name: http
protocol: TCP其中 spec.valumes 数组是Pod内容器可以访问的所有卷。containers.volumeMounts数组定义了挂载到特定容器中的卷以及每个卷 的挂载路径。Pod中的两个不同容器可以在不同的挂载路径上挂载同一个卷。
在应用程序中使用数据有多种方式
| 使用方式 | Volume 类型 | 生命周期 |
|---|---|---|
| 容器通信 | emptyDir | Pod |
| 缓存 | emptyDir | Pod |
| 持久数据 | NFS / 云存储 | 独立于 Pod |
| 访问宿主机 | hostPath | Node |
说人话
容器之间通信同步
两个容器通过共享Volume来协同工作,如
它们共享一个 emptyDir 类型的 Volume。
特点:
缓存数据
有些数据不是必须的,但能提高性能。例如
希望容器重启时缓存仍然存在,但不需要长期保存。emptyDir 也非常适合做缓存:
持久数据
有些数据必须长期保存,并且不依赖Pod声明周期。
要求:Pod重启后仍存在,Pod调度到其他节点时仍可访问。因此 Kubernets支持远程存储器。
| 存储类型 | 说明 |
|---|---|
| NFS | 网络文件系统 |
| iSCSI | 块存储协议 |
| Amazon EBS | AWS 块存储 |
| Azure Disk / Azure File | Azure 存储 |
| Google Persistent Disk | GCP 持久磁盘 |
volumes:
- name: kuard-data
nfs:
server: my.nfs.server.local
path: "/exports"含义:
my.nfs.server.local挂载宿主机文件系统
有些应用需要直接访问节点的文件系统。
/dev把Node上的目录挂载到容器
volumes:
- name: kuard-data
hostPath:
path: /var/lib/kuardhostPath有风险,Pod绑定到某个节点,不可移植,可能影响宿主机安全。
总结机制
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
volumes:
- name: kuard-data
nfs:
server: my.nfs.server.local
path: "/exports"
containers:
- name: kuard
image: gcr.io/kuar-demo/kuard-amd64:blue
ports:
- containerPort: 8080
name: http
protocol: TCP
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "256Mi"
volumeMounts:
- name: kuard-data
mountPath: "/data"
livenessProbe:
httpGet:
path: /healthy
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 30
timeoutSeconds: 1
periodSeconds: 10
failureThreshold: 3标签是键值对,可附加到Pod和ReplicaSets、Deployment、Service、Node、Namespace等Kubernetes对象上。标签可以是任意的,有助于为Kubernetes对象附加识别信息。标签是对对象进行分组的基础。
注解提供了一种类似标签的存储机制:键值对旨在保存工具和库可以利用的非识别信息。与标签不同, 注解并不用于查询、过滤或其他方式区分Pod。
| 类型 | 用途 |
|---|---|
| Label | 用来分类、筛选、选择对象 |
| Annotation | 用来存储额外信息 |
说人话:Label(标签)像仓库里给箱子贴的分类标签,Annotation(注解)像箱子上写的备注说明。
它是一个key/value 键值对
key: valueLabel Key 结构
可以分为两个部分,前缀可选,名称必须
[prefix/]nameprefix,必须是DNS子域名,最大长度253个字符,例如
acme.com/
kubernetes.io/
example.org/name规则,key的name部分必须存在,最大63个字符,必须以字母或数字开头结尾,中间允许
- _ .Label Value规则
value也是字符串,限制:最大63个字符、规则和key的name相同
示例Label
| Key | Value |
|---|---|
| acme.com/app-version | 1.0.0 |
| appVersion | 1.0.0 |
| app.version | 1.0.0 |
| kubernetes.io/cluster-service | true |
控制器依赖 label selector,找到带某些标签的一组Pod,然后对它们做点事情。
创建几个 Deployment(一种用于创建一组Pod的方式),并为它们添加一些有意思的标签(labels)
创建 alpaca-prod Deployment,并设置 ver、app、env标签。
$ kubectl run alpaca-prod \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--replicas=2 \
--labels="ver=1,app=alpaca,env=prod"创建 alpaca-test Deployment,并使用对应的值设置 ver、app、env标签。
$ kubectl run alpaca-test \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--replicas=1 \
--labels="ver=2,app=alpaca,env=test"为 bandicoot创建两个 Deployment
$ kubectl run bandicoot-prod \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--replicas=2 \
--labels="ver=2,app=bandicoot,env=prod"
$ kubectl run bandicoot-staging \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--replicas=1 \
--labels="ver=2,app=bandicoot,env=staging"目前,应该有了4个 Deployment
运行查看Deployment
$ kubectl get deployments --show-labels
NAME ... LABELS
alpaca-prod ... app=alpaca,env=prod,ver=1
alpaca-test ... app=alpaca,env=test,ver=2
bandicoot-prod ... app=bandicoot,env=prod,ver=2
bandicoot-staging ... app=bandicoot,env=staging,ver=2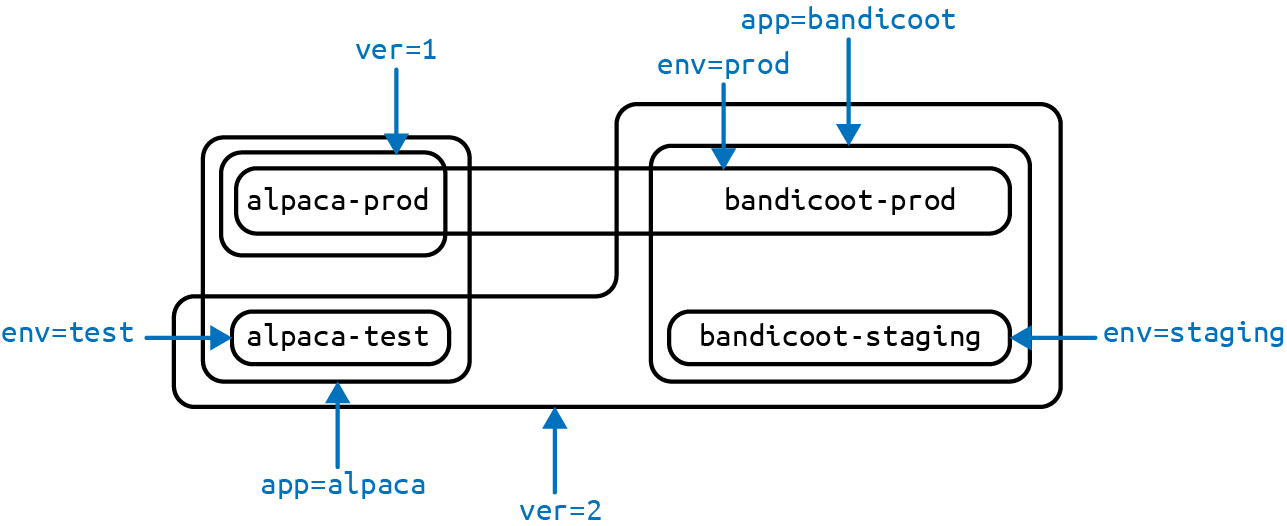
在对象创建之后,也可以给对象添加或更新标签
$ kubectl label deployments alpaca-test "canary=true"注意,这个例子 kubectl label 命令只会修改 Deployment 本身的标签。它不会影响 Deployment 创建的其他对象,例如 ReplicaSet 和 Pod。
可以使用 kubectl get 的 -L
选项,把某个标签的值显示为一列
$ kubectl get deployments -L canary
NAME DESIRED CURRENT ... CANARY
alpaca-prod 2 2 ... <none>
alpaca-test 1 1 ... true
bandicoot-prod 2 2 ... <none>
bandicoot-staging 1 1 ... <none>CANARY列显示的是每个Deployment的canary标签值。
删除标签,可以在标签名后面加一个 -
$ kubectl label deployments alpaca-test "canary-"Label 定义在 Kubernetes 对象的 metadata.labels 字段里。
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
env: prod
version: v1
spec:
containers:
- name: nginx
image: nginx:latest标签选择器(Label Selectors)用于根据一组标签来筛选 Kubernetes 对象。
每个Deployment通过ReplicaSet都会创建一组Pods,这些Pods的标签来自Deployment内部模板中定义的labels
$ kubectl get pods --show-labels
NAME ... LABELS
alpaca-prod-3408831585-4nzfb ... app=alpaca,env=prod,ver=1,...
alpaca-prod-3408831585-kga0a ... app=alpaca,env=prod,ver=1,...
alpaca-test-1004512375-3r1m5 ... app=alpaca,env=test,ver=2,...
bandicoot-prod-373860099-0t1gp ... app=bandicoot,env=prod,ver=2,...
bandicoot-prod-373860099-k2wcf ... app=bandicoot,env=prod,ver=2,...
bandicoot-staging-1839769971-3ndv ... app=bandicoot,env=staging,ver=2,...可能会注意,有个标签 pod-template-hash ,这个标签是
Deployment自动添加的,用于记录每个Pod是由 哪个版本的Pod模板生成的。这样
Deployment 在进行 更新(rolling update) 时就可以正确地管理不同版本的
Pods。
使用Selector过滤对象
如果只想查看 ver=2 的Pods,可以使用
--selector
kubectl get pods --selector="ver=2"
NAME READY STATUS RESTARTS AGE
alpaca-test-1004512375-3r1m5 1/1 Running 0 3m
bandicoot-prod-373860099-0t1gp 1/1 Running 0 3m
bandicoot-prod-373860099-k2wcf 1/1 Running 0 3m
bandicoot-staging-1839769971-3ndv5 1/1 Running 0 3m可以指定多个selector 用逗号分隔开,只有同时满足所有条件的对象才会返回。
kubectl get pods --selector="app=bandicoot,ver=2"
NAME READY STATUS RESTARTS AGE
bandicoot-prod-373860099-0t1gp 1/1 Running 0 4m
bandicoot-prod-373860099-k2wcf 1/1 Running 0 4m
bandicoot-staging-1839769971-3ndv5 1/1 Running 0 4m还可以查询,某个标签是否属于一组值中的一个,下面会返回
app=alpaca 或 app=bandicoot 的Pods。
kubectl get pods --selector="app in (alpaca,bandicoot)"
NAME READY STATUS RESTARTS AGE
alpaca-prod-3408831585-4nzfb 1/1 Running 0 6m
alpaca-prod-3408831585-kga0a 1/1 Running 0 6m
alpaca-test-1004512375-3r1m5 1/1 Running 0 6m
bandicoot-prod-373860099-0t1gp 1/1 Running 0 6m
bandicoot-prod-373860099-k2wcf 1/1 Running 0 6m
bandicoot-staging-1839769971-3ndv5 1/1 Running 0 6m可以判断,某个标签是否存在,例如查询所有带 canary 标签的 deployment
kubectl get deployments --selector="canary"
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
alpaca-test 1 1 1 1 7mSelector 操作符
| 操作符 | 说明 |
|---|---|
key=value |
key 等于 value |
key!=value |
key 不等于 value |
key in (value1,value2) |
key 的值是 value1 或 value2 |
key notin (value1,value2) |
key 的值不是 value1 或 value2 |
key |
key 存在 |
!key |
key 不存在 |
# 查询 ver=2 且 canary标签不存在 的Pod
kubectl get pods -l 'ver=2,!canary'一个Kubernetes对象可以使用 标签选择器 来引用一组其他 Kubernetes 对象。
例如,一个选择器
app=alpaca,ver in (1, 2)在API中会被转换为如下结构
selector:
matchLabels:
app: alpaca
matchExpressions:
- {key: ver, operator: In, values: [1, 2]}!= 运算符 无法直接表示,必须转换为 NotIn
表达式,并且只包含一个值
ver != 1
# 转换
operator: NotIn
values: [1]旧版本选择器语法,只支持 = 运算符。
app=alpaca,ver=1
# YAML表示
selector:
app: alpaca
ver: 1| 选择器类型 | 能力 | 使用场景 |
|---|---|---|
| 旧 selector | 只支持 = |
老 API:ReplicationController、Service |
| 新 selector | 支持 In / NotIn / Exists / DoesNotExist 等 |
Deployment、ReplicaSet 等 |
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: nginx
image: nginxDeployment 通过 label selector 找到它管理的Pod。如果selector写错,Deployment 找不到 Pod,集群 就会开始疯狂创建Pod。
Deployment
↓ selector
ReplicaSet
↓ selector
Pods例如更复杂的案例
selector:
matchLabels:
app: payment
matchExpressions:
- key: version
operator: In
values:
- v1
- v2
# 意思是
app = payment
AND
version ∈ {v1, v2}出让用户能阻止自己的基础设施以外,标签(Labels)在连接各种相关的Kubernetes对象方面起着 关键作用。
标签是一种强大且无处不再的“胶水”机制,把Kubernetes应用中的各个组件连接在一起。
Annotations 注解,提供了一种地方,用于为Kubernetes对象存储额外元数据,而这些 元数据的唯一目的是为了辅助工具和库的使用。
Labels用于识别和分组对象,而Annotations则用于提供关于对象的额外信息。
如果不确定,就先把信息存成annotation,如果后来发现需要用它做selector,在把它提升为label。
Annotation的Key规则,和Label完全一样。
Annotation的Value规则,是一个自由格式字符串,可以存任意数据,不会验证其格式。
Annotation的YAML定义,定义在所有Kubernetes对象的metadata部分
metadata:
annotations:
example.com/icon-url: "https://example.com/icon.png"kubectl delete deployments --allLabel = 用来“找对象” Annotation = 用来“记笔记”
| 类型 | 本质作用 | 给谁用 |
|---|---|---|
| Label | 用来 筛选、分组、关联资源 | Kubernetes 自己 + 用户 |
| Annotation | 用来 存储额外信息 | 工具、系统、脚本 |
metadata:
labels:
app: nginx
env: prod
annotations:
prometheus.io/scrape: "true"
scheduler.alpha.kubernetes.io/name: "custom-scheduler"Kubernetes是一个高度动态的系统,系统负责将Pod调度到各个节点上,确保它们正常运行,并在 需要时重新调度它们,还有一些机制可以根据系统负载自动调整 Pod 的数量。
Kubernetes引入了击中解决方案:
“在Kubernetes这种Pod随时可能消失的世界里,应用之间怎么相互找到对方。”
“在Kubernetes这种Pod随时可能消失的世界里,应用之间怎么相互找到对方。”
这类问题和解决方案的统称叫做服务发现 Service Disconvery。
服务发现工具用来解决这样一个问题:如何找到某个服务对应的进程,以及这鞋进程正在监听哪些网络地址。
好的服务发现系统具备以下特点:
DNS 与 服务发现
互联网中,传统的服务发现系统是 Domain Name System(DNS),被设计用于,相对稳定的名称解析,广泛且高效的缓存机制。
但在 动态变化的 Kubernetes 环境中,DNS显得不太合适。
很多系统在解析DNS名称时,会
导致客户端缓存过期的地址映射,客户端可能继续连接到错误的IP地址。
即使设置较短的 TTL Time-To-Live,并且客户端行为良好,也仍然存在一个自然延迟,DNS记录已经改变,客户端却还没意识到。
DNS查询在可返回的信息类型和数量上有天然限制,一个名称对应20-30个IP地址(A记录),系统变得不稳定,当DNS返回多个IP 时,大多数客户端处理方式是,只使用第一个IP,依赖DNS服务器对记录顺序进行随机化或轮询。
在Kubernetes中,真正的服务发现(service disconvery)是从 Service 对象开始的。
下面创建一些 Deployment 和 Service
# 创建Deployment
$ kubectl create deployment alpaca-prod \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--port=8080
# 扩容Pod数量
$ kubectl scale deployment alpaca-prod --replicas 3
# 创建Service
$ kubectl expose deployment alpaca-prod
# 创建Deployment
$ kubectl create deployment bandicoot-prod \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--port=8080
# 扩容Pod数量
$ kubectl scale deployment bandicoot-prod --replicas 2
# 创建Service
$ kubectl expose deployment bandicoot-prod查看当前 Service
$ kubectl get services -o wide
NAME CLUSTER-IP ... PORT(S) ... SELECTOR
alpaca-prod 10.115.245.13 ... 8080/TCP ... app=alpaca
bandicoot-prod 10.115.242.3 ... 8080/TCP ... app=bandicoot
kubernetes 10.115.240.1 ... 443/TCP ... <none>有三个Service,其中 alpaca-prod 和 bandicoot-prod 是刚才创建的,kubernetes 这个Service是系统自动创建的, 其作用是让集群内部的应用可以找到并访问 Kubernetes API Server。
Service会被分配一个新的虚拟IP,叫做 Cluster IP,Cluster IP是一种特殊的IP地址,系统会使用它对selector匹配到的 所有 Pod 进行负载均衡。
Service (ClusterIP)
│
▼
Pod1 Pod2 Pod3Service 本质
Service ≈ 名字 + label selector + 负载均衡 + 虚拟IP它解决的问题只有一个,Pod IP会变,但 Service IP永远不变。
# Deployment创建Pod
Deployment
│
▼
ReplicaSet
│
▼
Pods (3个)
# Service 发现Pod
# Service 不会创建Pod,只是找到Pod
Service
│
selector
│
▼
Pods由于 Cluster IP是虚拟IP,是稳定的,适合为它分配一个DNS地址。
在同一命名空间内,只需要使用Service名称,就可以连接到该Service所标识的一组Pod中的某一个。
Kubernetes为运行在集群中的Pod提供了DNS服务,这个DNS服务在创建集群时作为系统组件安装。
Kubernetes 的 DNS 服务会为 Cluster IP 提供 DNS 名称解析。
如 Service alpaca-prod 的DNS完整名称是:
alpaca-prod.default.svc.cluster.local.Kubernetes做了非常使用的事
| 功能 | 作用 |
|---|---|
| Service | 提供稳定的虚拟 IP |
| DNS | 给 Service 提供稳定域名 |
| Pod | 可以直接用域名访问 Service |
Pod之间通信变成了
curl http://service-name一个应用在刚启动时不能立即处理请求,一般都会有初始化过程。
Kubernetes的Service对象有一个实用功能,可以通过 readiness check(就绪检查),来跟踪哪些Pod 已经准备好接收流量。
可以修改 deployment,为Pod添加一个 readiness check
$ kubectl edit deployment/alpaca-prod添加以下配置
spec:
...
template:
...
spec:
containers:
...
name: alpaca-prod
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 2
initialDelaySeconds: 0
failureThreshold: 3
successThreshold: 1Deployment更新后的行为,当更新deployment配置后,现有的 alpaca Pod会被删除并重建。
观察Service的Endpoints
$ kubectl get endpoints alpaca-prod --watchEndpoints是一种更底层的机制,用于查看Service实际把流量发给哪些Pod。
目前,本章讨论的内容都是关于在Kubernetes集群内部保留服务,很多时候,Pod的IP地址只能在集群内访问。
实现新的流量从外部流入,最通用最可移植的方法是 NodePort 的功能,进一步增强Service的能力。
kubectl edit service alpaca-prod
# 把sepc.type字段改成NodePort
# 在创建Service时也可以直接指定,系统随后会为该 Service 分配一个新的 NodePort
kubectl expose --type=NodePort查看Service信息
kubectl describe service alpaca-prod
Name: alpaca-prod
Namespace: default
Labels: app=alpaca
Annotations: <none>
Selector: app=alpaca
Type: NodePort
IP: 10.115.245.13
Port: <unset> 8080/TCP
NodePort: <unset> 32711/TCP
Endpoints: 10.112.1.66:8080,10.112.2.104:8080,10.112.2.105:8080
Session Affinity: None
No events.系统为该 Service 分配了 32711 端口。现在可以通过任意一个集群节点的IP + 这个端口访问该服务。
如果你和集群节点在同一个网络中,可以访问
http://<node-ip>:32711如果集群部署在云上,可以通过SSH隧道访问,例如
ssh <node> -L 8080:localhost:32711然后在浏览器访问,就会连接到该Service
http://localhost:8080负载均衡行为,每次发送请求时,请求都会被随机转发到实现该 Service 的某一个Pod。
NodePort本质
外部请求
↓
NodeIP:NodePort
↓
Service
↓
随机转发
↓
Pods所以访问路径其实是:
浏览器 → NodeIP:32711 → Service → PodLoadBalancer是在NodePort类型的基础上构建的,它会额外让云平台创建一个新的负载均衡器, 并把流量转发到集群中的节点。
修改 alpaca-prod Service
kubectl edit service alpaca-prod
# 把 sepc.type 修改为 LoadBalancer创建 LoadBalancer类型的Service会把这个服务暴露到公共互联网。
立即执行
kubectl get services
# 会看到 alpaca-prod的EXTERNAL-IP显示<pending>一会,云平台会分配一个公网地址$ kubectl describe service alpaca-prod
Name: alpaca-prod
Namespace: default
Labels: app=alpaca
Selector: app=alpaca
Type: LoadBalancer
IP: 10.115.245.13
LoadBalancer Ingress: 104.196.248.204
Port: <unset> 8080/TCP
NodePort: <unset> 32711/TCP
Endpoints: 10.112.1.66:8080,10.112.2.104:8080,10.112.2.105:8080
Session Affinity: None
Events:
FirstSeen ... Reason Message
--------- ... ------ -------
3m ... Type NodePort -> LoadBalancer
3m ... CreatingLoadBalancer Creating load balancer
2m ... CreatedLoadBalancer Created load balancer上面例子是 Google Cloud Platform的GKE创建和管理的集群,不同云平台创建负载均衡器的方式是不同的。
上面的例子是 外部负载均衡器(External Load Balancer)连接到公共互联网的负载均衡器,这种方式适合把服务暴露给全世界。
很多情况希望,在私有网络内部访问应用程序,可以使用 内部负载均衡器(Internal Load Balancer)
通常通过 Service Annotation 对象注解来配置。
在 Azure Kubernetes Service (AKS) 中创建内部负载均衡器,需要添加 annotation:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"Amazon Web Services
service.beta.kubernetes.io/aws-load-balancer-internal: "true"Alibaba Cloud
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet"Google Cloud Platform
cloud.google.com/load-balancer-type: "Internal"当你给 Service 添加这个 annotation 时,配置会像这样:
...
metadata:
...
name: some-service
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
...创建带有这些 annotation 的 Service 后:系统会创建一个仅在内部网络可访问的负载均衡器,而不是暴露到公网。
有些程序希望在不适用 Cluster IP的情况下使用服务,为此,Kubernetes 提供了另一种对象类型,叫做 Endpoints 对象。
对于每一个 Service 对象,Kubernetes 都会自动创建一个对应的 Endpoints 对象,其中包含该服务所对应的 IP 地址列表:
$ kubectl describe endpoints alpaca-prod
Name: alpaca-prod
Namespace: default
Labels: app=alpaca
Subsets:
Addresses: 10.112.1.54,10.112.2.84,10.112.2.85
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
<unset> 8080 TCP
No events.要使用某个服务,一个更高级的应用程序可以直接与 Kubernetes API 交互,查询这些 endpoints,然后直接调用它们。
Kubernetes API 甚至支持一种叫做 “watch(监听)” 的能力,可以在对象发生变化时立即收到通知。
这样一来,当与某个服务关联的 IP 地址发生变化时,客户端可以立刻做出响应。
示例
一个终端窗口中运行以下命令,并保持它持续运行
$ kubectl get endpoints alpaca-prod --watch它会输出当前的endpoint状态,然后命令会挂起等待变化
NAME ENDPOINTS AGE
alpaca-prod 10.112.1.54:8080,10.112.2.84:8080,10.112.2.85:8080 1m打开其他终端,删除并重建 alpaca-prod 提供服务的Deployment
$ kubectl delete deployment alpaca-prod
$ kubectl create deployment alpaca-prod \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--port=8080
$ kubectl scale deployment alpaca-prod --replicas=3随着这些Pods被删除并重新创建,命令观察endpoints输出中的IP地址列表会实时更新
NAME ENDPOINTS AGE
alpaca-prod 10.112.1.54:8080,10.112.2.84:8080,10.112.2.85:8080 1m
alpaca-prod 10.112.1.54:8080,10.112.2.84:8080 1m
alpaca-prod <none> 1m
alpaca-prod 10.112.2.90:8080 1m
alpaca-prod 10.112.1.57:8080,10.112.2.90:8080 1m
alpaca-prod 10.112.0.28:8080,10.112.1.57:8080,10.112.2.90:8080 1m核心思想总结:
Kubernetes 的 Service 是建立在对Pod的标签选择器之上的。
使完全不使用 Service 对象,你也可以通过 Kubernetes API 实现一种最基础的服务发现机制。
$ kubectl get pods -o wide --show-labels
NAME ... IP ... LABELS
alpaca-prod-12334-87f8h ... 10.112.1.54 ... app=alpaca
alpaca-prod-12334-jssmh ... 10.112.2.84 ... app=alpaca
alpaca-prod-12334-tjp56 ... 10.112.2.85 ... app=alpaca
bandicoot-prod-5678-sbxzl ... 10.112.1.55 ... app=bandicoot
bandicoot-prod-5678-x0dh8 ... 10.112.2.86 ... app=bandicoot只查看alpaca应用的Pod
$ kubectl get pods -o wide --selector=app=alpaca
# 输出示例
NAME ... IP ...
alpaca-prod-3408831585-bpzdz ... 10.112.1.54 ...
alpaca-prod-3408831585-kncwt ... 10.112.2.84 ...
alpaca-prod-3408831585-l9fsq ... 10.112.2.85 ...到这,已经具备最基本的服务发现能力
现实很快会给你一巴掌。因为维护正确的 label 集合并让客户端同步使用它们其实很麻烦。 这正是 Service 对象被设计出来的原因。
手动服务发现
Label → 找 Pod → 拿 IPService的作用把这套流程自动化
Service
↓
自动根据 label 找 Pod
↓
提供稳定的访问入口 (ClusterIP / DNS)Cluster IP是一种稳定的虚拟IP地址,会把流量负载均衡到某个Servce的所有Endpoints(后端Pod)上。
这种“魔法”由运行在集群每个节点上的组件 kube-proxy 完成的。
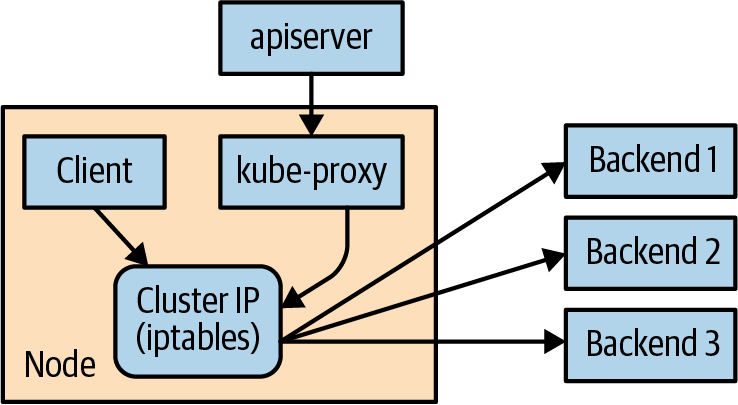
kube-proxy 会通过 API Server 持续监听集群中新创建的Service。 一旦发现新Service,就在该节点Linux内核中配置一组 iptables 规则, 这些规则会重写数据包的目标地址,从而把请求转发到Service的某一个Endpoint。
如果某个 Service 的 Endpoints 发生变化
那么对应的 iptables 规则也会被重新写入和更新。
Cluster IP 的分配,是在 Service 创建时由 API Server 自动分配的。但也能用户手动指定一个 Cluster IP,一旦cluster IP 被设置,就不能再修改。
想修改,只能
Kubernetes 的 Service IP 地址范围是通过 kube-apiserver
启动参数配置的:
--service-cluster-ip-range这个地址范围必须满足几个条件:
--service-cluster-ip-range 指定的范围,不能已经被其他
Service 使用虽然大多数用户应该用DNS服务来查找Cluster IP,仍存在一些较旧的及其被使用,一种方法是 再Pod启动时向其注入一组环境变量。
不要用,不要用,知道就好了。
虽然在 Kubernetes 集群内部拥有服务发现功能非常方便,但在现实世界中,很多应用实际上需要把 部署在 Kubernetes 中的云原生应用 与 部署在传统(legacy)环境中的应用 进行集成。
Kubernetes 解决了 集群内部通信,但 跨环境通信(cloud ↔︎ on-prem ↔︎ legacy) 依然是工程师每天头疼的地方。
后来出来一堆东西:
都在解决一个问题:不同环境里的服务怎么优雅地互相说话。
需要让 Kubernetes 访问集群外部的旧系统(legacy resources) 时,可以使用一种叫做 无 selector 的 Service(selector-less service) 的方式。
允许你声明一个 Kubernetes Service,并为它 手动指定一个位于集群外部的 IP 地址。这样做的好处是:
创建无selector的Service
删除 sepc.selector 字段,但保留 metadata 和 ports
配置。
因为这个Service没有selector,Kubernetes不会自动创建 Endpoints,所以你必须手动创建 Endpoints。
手动添加Endpoints
通常情况下,你添加的 endpoint 会是一个固定 IP,例如:
因为 IP 通常不会变,所以一般只需要添加一次。但如果 IP 地址发生变化,你就必须 更新对应的 Endpoints 资源。
创建Endpoints示例
可以创建或更新一个 Endpoints 资源,例如:
apiVersion: v1
kind: Endpoints
metadata:
# 这个名字必须和 Service 的名字完全一致
name: my-database-server
subsets:
- addresses:
# 把这个 IP 替换成你的真实服务器 IP
- ip: 1.2.3.4
ports:
# 替换为你需要暴露的端口
- port: 1433这套机制的实际效果:
假设有 service my-database-server
Pod访问
my-database-server.default.svc.cluster.localDNS 解析没问题,但流量实际上走的是:
Pod -> Service -> Endpoint -> 1.2.3.4:1433
Kubernetes Pod
↓
Kubernetes Service
↓
手动 Endpoints
↓
外部数据库服务器将外部资源连接到 Kubernetes 集群内部的服务会稍微复杂一些。
如果你的云服务提供商支持,最简单的方法是创建一个“内部(internal)负载均衡器”。正如前面介绍的那样,这种负载均衡器运行在你的虚拟私有网络(VPC)中,并可以通过一个固定 IP 地址 把流量转发到 Kubernetes 集群内部。
如果没有内部负载均衡器可用,你可以使用 NodePort Service,把服务暴露到集群节点的 IP 地址上。
接下来有两种方式可以把流量分发到这些节点:
如果以上两种方案都不适合你的场景,还可以使用更复杂的方案,例如:
在外部资源机器上运行完整的 kube-proxy,并配置该机器使用 Kubernetes 集群内部的 DNS 服务器。
不过这种方案非常难正确配置,因此通常只建议在 本地部署(on-premise)环境中使用。
外部系统访问 Kubernetes 服务的常见方案,从简单到复杂:
删除 label 有 app的service与deployment
$ kubectl delete services,deployments -l appService 解决“服务在哪”
Ingress是英语单词,意思 进入、入口、进入的通道。反义词是 Egress 出口、离开。Ingress 就是“进入集群的流量入口规则”。
任何应用的一个关键部分都是让网络流量进出该应用程序,Kubernetes有一套功能,可以让服务暴露在集群之外。
Service对象工作在OSI模型的第四层 L4,意味着它只能转发 TCP 和 UDP连接,不会查看这些连接的内部内容。
| 层级 | 名称 | 主要作用 | 常见协议 / 技术 |
|---|---|---|---|
| 7 | 应用层(Application) | 给应用程序提供网络服务 | HTTP、HTTPS、FTP、SMTP、DNS |
| 6 | 表示层(Presentation) | 数据格式转换、加密、压缩 | TLS/SSL、JPEG、MPEG |
| 5 | 会话层(Session) | 建立、管理、终止会话连接 | NetBIOS、RPC |
| 4 | 传输层(Transport) | 端到端传输、可靠性控制 | TCP、UDP |
| 3 | 网络层(Network) | 路由选择、IP寻址 | IP、ICMP、IPsec |
| 2 | 数据链路层(Data Link) | MAC地址、帧传输、差错检测 | Ethernet、PPP |
| 1 | 物理层(Physical) | 比特流传输,电信号 | 网线、光纤、无线电 |
以前,在单个IP地址上托管多个HTTP网站,通常做法是使用负载均衡器或反向代理来接受HTTP(80端口)和 HTTPS(443)的入站连接。
Kubernetes 将其基于 HTTP 的负载均衡系统统称为 Ingress。
Ingress控制器由两部分组成:
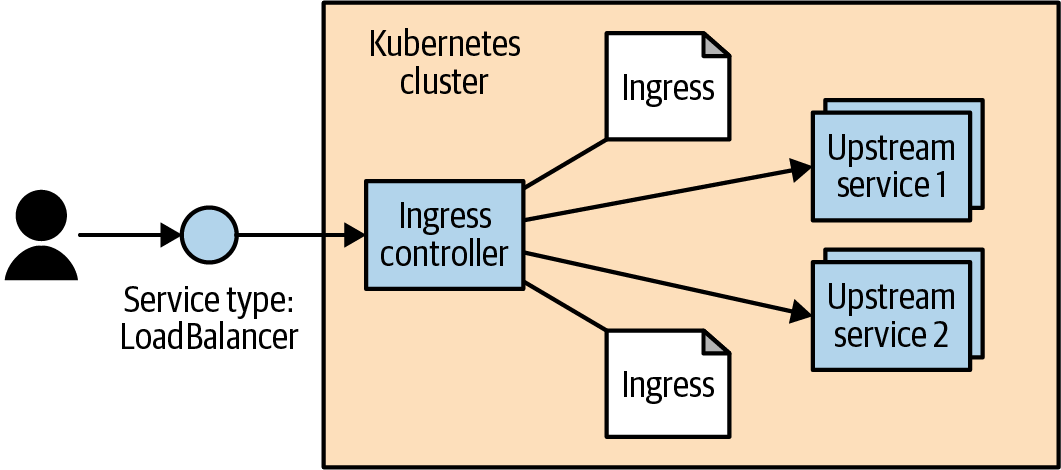
Ingress被拆分为两部分:通用资源规范(Ingress Spec)和 控制器实现(Ingress Controllers)。
Kubernetes本身并不内置“标准”Ingress控制器,用户必须自行安装众多可选实现之一。
Contour 是一个用于配置开源负载均衡器 Envoy(CNCF 项目)的控制器。Envoy 是通过 API 动态配置的。Contour Ingress 控制器负责将 Ingress 对象转换为 Envoy 能理解的配置。
https://github.com/projectcontour/contour
# 这条命令需要由具有 cluster-admin 权限的用户执行
$ kubectl apply -f https://projectcontour.io/quickstart/contour.yaml它会创建一个名为 projectcontour 的命名空间,在该命名空间内,会创建一个Deployment(副本数为2)以及一个面向 外部的LoadBalancer类型的Service。
它会通过服务账户设置正确的权限,并安装一个 CustomResourceDefinition。
安装完成后,可以通过以下命令获取 Contour 的外部地址:
$ kubectl get -n projectcontour service envoy -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) ...
contour 10.106.53.14 a477...amazonaws.com 80:30274/TCP ...查看 EXTERNAl-IP 列,可以是IP地址(在GCP或Azure上) 或
主机名(AWS上)。
如果你的Kubernetes集群不支持LoadBalancer类型的Service,需要修改Contour安装YAML,将Service类型改为NodePort, 并通过适合你环境的方式将流量路由到集群内的节点。
如果使用 minikube,通常 EXTERNAL-IP
不会显示任何值,解决方法是在另一个终端执行
minikube tunnel这会配置网络路由,使每个 LoadBalancer 类型的 Service 都能分配到唯一的 IP 地址。
为了让 Ingress 正常工作,你需要将 DNS 条目指向负载均衡器的外部地址。
ExternalDNS 项目是一个可以帮你管理 DNS 记录的集群附加组件。ExternalDNS 会监控你的 Kubernetes 集群,并将 Kubernetes Service 资源的 IP 地址同步到外部 DNS 提供商。ExternalDNS 支持多种 DNS 提供商,包括传统域名注册商以及公共云服务提供商。
也就是让集群的Ingress EXTERNAL-IP
同步到自己的域名商DNS解析去。
https://github.com/kubernetes-sigs/external-dns
如果你没有域名,正在使用像minikube这样的本地解决方案,可以通过
/etc/hosts 文件进行本地配置
启动 ip-address 就是 Contour的 EXTERNAL-IP
外部IP地址。
<ip-address> alpaca.example.com bandicoot.example.com配置好了 Ingress 控制器,首先创建几个上游服务进行试验
# 创建deployment
$ kubectl create deployment be-default \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--replicas=3 \
--port=8080
# 为deployment暴露service
$ kubectl expose deployment be-default
$ kubectl create deployment alpaca \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--replicas=3 \
--port=8080
$ kubectl expose deployment alpaca
$ kubectl create deployment bandicoot \
--image=gcr.io/kuar-demo/kuard-amd64:purple \
--replicas=3 \
--port=8080
$ kubectl expose deployment bandicoot
$ kubectl get services -o wide有以下Service列表,每个Deployment都对应一个Service,Ingress将用这些服务来路由外部流量。
| NAME | CLUSTER-IP | PORT(S) | SELECTOR |
|---|---|---|---|
| alpaca | 10.115.245.13 | 8080/TCP | run=alpaca |
| bandicoot | 10.115.242.3 | 8080/TCP | run=bandicoot |
| be-default | 10.115.246.6 | 8080/TCP | run=be-default |
| kubernetes | 10.115.240.1 | 443/TCP |
Ingress最简单的用法是将它看到的所有请求“原样”转发到上游服务器。
simple-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-ingress
spec:
defaultBackend:
service:
name: alpaca
port:
number: 8080可以使用 kubectl apply 创建这个 Ingress
$ kubectl apply -f simple-ingress.yaml
ingress.extensions/simple-ingress created
$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
simple-ingress * 80 13m
$ kubectl describe ingress simple-ingress
Name: simple-ingress
Namespace: default
Address:
Default backend: alpaca:8080
(172.17.0.6:8080,172.17.0.7:8080,172.17.0.8:8080)
Rules:
Host Path Backends
---- ---- --------
* * alpaca:8080 (172.17.0.6:8080,172.17.0.7:8080,172.17.0.8:8080)
Annotations:
...
Events: <none>这就意味着,任何访问 Ingress 控制器的HTTP请求都会转发到 alpaca 服务,此时, 可以通过服务的任意原始IP或CNAME访问alpaca实例。
在这一阶段,这种配置相比直接使用 type: LoadBalancer
的服务并没有太大优势。
当根据请求的属性来引导流量时,最常见的例子是让Ingress系统查看HTTP的Host头,并根据该头来引导流量。
再创建一个Ingresss
host-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: host-ingress
spec:
defaultBackend:
service:
name: be-default
port:
number: 8080
rules:
- host: alpaca.example.com
http:
paths:
- pathType: Prefix
path: /
backend:
service:
name: alpaca
port:
number: 8080alpaca.example.comhttp.paths: 匹配请求路径
pathType: Prefix: 前缀匹配,标识请求路径以
/ 开头的都会匹配path: /: 匹配的路径前缀backend.service.name: 匹配到这个 host + path
的请求会转发到名为 alpaca 的Servicebackend.service.port.number: 服务端口号,8080kubectl apply 创建这个 Ingress。
$ kubectl apply -f host-ingress.yaml
ingress.extensions/host-ingress created
$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
host-ingress alpaca.example.com 80 54s
simple-ingress * 80 13m
$ kubectl describe ingress host-ingress
Name: host-ingress
Namespace: default
Address:
Default backend: be-default:8080 (<none>)
Rules:
Host Path Backends
---- ---- --------
alpaca.example.com
/ alpaca:8080 (<none>)
Annotations:
...
Events: <none>不仅根据主机名,还根据HTTP请求中的路径来引导流量。
例如,将所有进入 http://bandicoot.example.com
的流量引导到 bandicoot 服务,但将
http://bandicoot.example.com/a 的流量引导到 alpaca
服务。这种场景可以在单个域的不同路径上托管多个服务。
path-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: path-ingress
spec:
rules:
- host: bandicoot.example.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: bandicoot
port:
number: 8080
- pathType: Prefix
path: "/a/"
backend:
service:
name: alpaca
port:
number: 8080上面例子,以 /a/ 开头的流量会转发到 alpaca 服务,其他以
/ 开头的流量会被转发到 bandicoot 服务。
当请求被代理到上游服务时,路径保持不变。
$ kubectl delete ingress host-ingress path-ingress simple-ingress
$ kubectl delete service alpaca bandicoot be-default
$ kubectl delete deployment alpaca bandicoot be-default存在多种Kubernetes Ingress控制器实现,而且在同一个集群中运行多个Ingress控制器也是常见需求。
为了解决这种情况,引入了 IngressClass 资源,当创建 Ingress 资源时,可以通过字段
sepc.ingressClassName指定使用哪一个 IngressClass。
Kubernetes 1.18之前,IngressClassName 字段并不存在,使用 annotation 来指定控制器
kubernetes.io/ingress.class如果Ingress资源中没设置 spec.ingressClassName 则会使用 默认的 Ingress 控制器。默认控制器的 指定方式是在 对应的 IngressClass 资源上添加 annotation
ingressclass.kubernetes.io/is-default-class比如,集群里同时跑
可以这样选择
spec:
ingressClassName: nginx或者
spec:
ingressClassName: traefik这样不同的 Ingress 规则就会被不同控制器处理。
说人话,“多个Ingress controller 抢活干,所以Kubernetes给它们发了工作标签”
如果定义了多个Ingress对象,Ingress控制器通常会读取所有这些对象,并尝试把它们合并成一个一致的配置。
如果你在这些 Ingress 对象中定义了重复或互相冲突的配置,那么系统的行为就是未定义的。
“多个Ingress可以一起使用,但别写冲突配置,否则结果看运气。”
出于非常谨慎的安全考虑,一个Ingress对象只能引用同一个Namespace中的上游Service。意味着你不能使用一个 Ingress 对象,把某个子路径指向另一个 Namespace 的 Service。
不同Namespace中的多个Ingress对象,可以为同一个主机名(host)指定不同的子路径(subpath)。这些 Ingress 对象最终会被 Ingress Controller 合并,从而生成最终的 Ingress 配置。
跨 Namespace 的行为意味着:在整个 集群范围内协调 Ingress 配置是非常必要的。
某些Ingress控制器实现支持一种可选功能:路径重写(Path Rewriting)
它可以在 HTTP 请求被代理到后端服务时,对请求路径进行修改。
例如,如果使用 NGINX Ingress Controller,可以添加如下 annotation:
nginx.ingress.kubernetes.io/rewrite-target: /例如域名访问 example.com/aservice/q,如果 Ingress
负责Path是 example.com/aservice, 且加了重写,就会重写为
/q 发到上游的
Service,Service中的Pod进程接收到Http请求,Path就是 /q
了。
NGINX Ingress Controller 还允许在路径中使用正则表达式。
和反向代理相关知识差不多。
先,用户需要创建一个包含 TLS 证书和私钥的 Secret,你也可以使用 kubectl 命令式地创建Secret:
kubectl create secret tls <secret-name> \
--cert <certificate-pem-file> \
--key <private-key-pem-file>YAML tls-secret.yaml
apiVersion: v1
kind: Secret
metadata:
creationTimestamp: null
name: tls-secret-name
type: kubernetes.io/tls
data:
tls.crt: <base64 encoded certificate>
tls.key: <base64 encoded private key>创建好 Secret 之后,就可以在 Ingress 对象中引用它,在Ingress中需要指定,证书对应主机名,使用的Secret名称。
tls-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-ingress
spec:
tls:
- hosts:
- alpaca.example.com
secretName: tls-secret-name
rules:
- host: alpaca.example.com
http:
paths:
- backend:
serviceName: alpaca
servicePort: 8080TLS Secret管理问题
上传和管理 TLS Secret 其实挺麻烦的,而且证书往往还 价格不低,有一个非营利组织 Let’s Encrypt 提供免费的 证书颁发机构(CA),而且是 API 驱动的。
Let’s Encrypt是API驱动的,所以可以构建一个Kubernetes集群,
cert-manager,实现自动化证书管理的关键组件是 cert-manager。通过cert-manager Kubernetes可以
有许多不同的Ingress Controller实现,每一种都在基础的Ingress对象之上构建,并提供各自独特的功能。
每个云服务提供商通常都会提供自己的 Ingress 实现,用来暴露该云平台特定的 七层(L7)负载均衡器。这些控制器不会在 Pod 中运行软件负载均衡器,而是读取 Ingress 对象,并通过 API 使用这些对象去配置云平台提供的负载均衡服务。
最流行的通用 Ingress Controller 很可能是 NGINX Ingress Controller(开源版)。需要注意的是,还有一个基于 NGINX Plus(商业版) 的控制器。
开源版 NGINX Ingress Controller 的工作方式基本是:
开源版 NGINX 控制器提供了非常多的功能和选项,这些功能大多通过 annotations(注解) 来配置。
Emissary 和 Gloo 是另外两种基于 Envoy 的 Ingress Controller,它们更专注于充当 API Gateway(API 网关)。
Traefik 是一个用 Go 语言实现的反向代理,同时也可以作为 Ingress Controller 使用。它提供了一系列功能和可视化仪表盘,对开发者来说非常友好。
| 类型 | 代表 | 特点 |
|---|---|---|
| 云厂商型 | AWS ALB / GCP LB / Azure LB | 直接调用云负载均衡 |
| Nginx 系 | NGINX Ingress | 最流行,功能极多 |
| Envoy 系 | Emissary / Gloo | API Gateway 场景 |
| Go Proxy | Traefik | 开发者友好,带 Dashboard |
Ingress对象为配置L7(第七层)负载均衡器提供了非常有用的抽象层。
对于 Kubernetes 来说,HTTP 负载均衡的未来很可能是 Gateway API。该项目目前正由 Kubernetes 的网络特别兴趣小组(SIG)积极开发。
https://github.com/kubernetes-sigs/gateway-api
Gateway API 项目的目标是为 Kubernetes 中的流量路由提供一个 更现代化的 API。虽然它主要关注 HTTP 负载均衡,但 Gateway API 也包含用于控制 第四层(TCP)负载均衡 的资源。
总结一下潜台词:
在 Kubernetes中,Ingress是一个比较特殊的系统,它本身只是一个资源规范(schema),而实现这个规范 的 Ingress Controller 需要单独安装和管理。
Ingress 依然是一个非常关键的组件,因为它能够以实用且成本高效的方式将服务暴露给外部用户。
Pod本质上是一次性的单例实例,大多数情况下,会希望在某个时间同时运行同一个容器的 多个副本,原因有:
ReplicaSet充当的是一种集群级别的Pod管理器,确保正确类型和数量的Pod始终在运行。
由于ReplicaSet让创建和管理Pod副本变得非常容易,它成为了许多常见应用部署模式以及 基础设施级自愈(self-healing)应用的构建基础。
管理Pod副本的实际过程,是一种 调谐循环(reconciliation loop)的例子, 这种循环是Kubernetes设计和实现中的核心机制之一。
期望状态 (desired state)
↓
当前状态 (current state)
↓
控制器不断对比
↓
修复差异比如,想要3个Pod,实际只有2个,ReplicaSet控制器就会自动创建1个Pod。
调谐循环背后的核心概念是:期望状态(Desired State) 与 当前状态(Observed / Current State)。
期望状态是指你希望系统达到的状态。当前状态(Current State)则是系统实际观察到的状态。
例如“期望状态是:运行 3 个 运行 kuard 服务器 的 Pod 副本。”
“当前状态是:当前只有 2 个 kuard Pod 在运行。”
调谐循环的工作方式
优点:
while (true) {
当前状态 = 观察系统
如果 当前状态 != 期望状态
执行操作让系统接近期望状态
}ReplicaSet与Pod之间的关系是松耦合的。
ReplicaSet会创建并管理Pod,但它并不拥有Pod。ReplicaSet通过 标签查询 来识别它应该管理的一组Pod。
类似的
ReplicaSet ---> 创建 Pod
│
│ (通过 label selector 找)
▼
Pod
Service ---> 根据 label 把流量分发到 Pod虽然声明式配置非常有价值,有时命令式方式更容易快速构建系统。
某个时刻,可能希望把单实例容器扩展成一个可复制的服务,并创建和管理一组类似的容器实例。
创建ReplicaSet,接管已有Pod,并继续扩展出更多相同的容器副本,可以平滑地从一个命令式创建的单 Pod,过渡到由 ReplicaSet 管理的多个 Pod 副本,而不会产生服务中断。
Pod可以先手动创建
kubectl run mypod ...之后再创建 ReplicaSet,只要 labels 匹配,ReplicaSet就会,自动接管这个Pod
再扩容,ReplicaSet会继续创建更多Pod。
有时,当服务器出现异常时,Pod级别的健康检查会自动重启Pod.
在这种情况下,你当然可以直接杀掉这个 Pod。但这样做会让开发者只能通过日志来排查问题。
一种更好的方法是:修改这个异常 Pod 的标签(labels)集合。使得 Pod 与 ReplicaSet 以及 Service解除关联。
既保证了 服务可用性,又给开发者完整的调试环境。
ReplicaSet的设计目标,是在系统架构中表示一个单一、可扩展的微服务。
一般来说,ReplicaSet主要用于无状态 或 接近无状态的服务。
它创建的这些Pod是可以互相替换的,当 ReplicaSet 被缩容(scale down)时, 系统会随机选择一个 Pod 删除。在这种缩容操作下,你的应用程序不应该发生任何行为变化。
ReplicaSet是Deployment在底层使用的机制,理解ReplicaSet的工作方式仍然很重要,排查问题可能 需要直接调试ReplicaSet的行为。
Deployment
↓
ReplicaSet
↓
PodsDeployment负责版本管理、滚动更新、回滚,ReplicaSet只干一件事 “保证 Pod 的数量始终等于你声明的数量”
每个ReplicaSet都必须包含以下内容:
实例,kuard-rs-yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
labels:
app: kuard
version: "2"
name: kuard
spec:
replicas: 1
selector:
matchLabels:
app: kuard
version: "2"
template:
metadata:
labels:
app: kuard
version: "2"
spec:
containers:
- name: kuard
image: "gcr.io/kuar-demo/kuard-amd64:green"
ports:
- containerPort: 80ReplicaSet spec中的 selector 必须是 Pod模板中的labels的真子集。
selector ⊂ podTemplate.labels上面的 kuard-rs.yaml
$ kubectl apply -f kuard-rs.yaml
replicaset "kuard" created当 kuard ReplicaSet 被成功接收后,ReplicaSet 控制器会检测当前集群状态。
如果发现没有任何 kuard Pod 运行并满足期望状态,它就会根据 Pod 模板(Pod template) 的内容创建一个新的 kuard Pod。多了的话还会缩容。
和其他Kubernetes对象一样,想看某个 ReplicaSet 的更详细信息,可以使用 describe 命令 来获取它的完整状态信息。
root@ser745692301841:/dev_dir/note# kubectl get replicaSet
NAME DESIRED CURRENT READY AGE
avant-deployment-75f5fc4b49 3 3 3 3h46m
root@ser745692301841:/dev_dir/note# kubectl get rs
NAME DESIRED CURRENT READY AGE
avant-deployment-75f5fc4b49 3 3 3 3h47m
root@ser745692301841:/dev_dir/note# kubectl describe rs avant-deployment-75f5fc4b49
Name: avant-deployment-75f5fc4b49
Namespace: default
Selector: app=avant,pod-template-hash=75f5fc4b49
Labels: app=avant
pod-template-hash=75f5fc4b49
Annotations: deployment.kubernetes.io/desired-replicas: 3
deployment.kubernetes.io/max-replicas: 4
deployment.kubernetes.io/revision: 1
Controlled By: Deployment/avant-deployment
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=avant
pod-template-hash=75f5fc4b49
Containers:
avant:
Image: gaowanlu/avant:latest
Port: 20023/TCP (http)
Host Port: 0/TCP (http)
Limits:
cpu: 2
memory: 512Mi
Requests:
cpu: 1
memory: 128Mi
Liveness: http-get http://:20023/ delay=120s timeout=10s period=30s #success=1 #failure=5
Readiness: http-get http://:20023/ delay=120s timeout=10s period=30s #success=1 #failure=5
Environment: <none>
Mounts:
/avant_static from avant-data (rw)
Volumes:
avant-data:
Type: HostPath (bare host directory volume)
Path: /var/www/html
HostPathType:
Node-Selectors: <none>
Tolerations: <none>
Events: <none>有时候可能会想知道,某个Pod是否由某个 ReplicaSet 管理。
为了支持这种查询,ReplicaSet 控制器会在它创建的每一个Pod中添加一个
ownerReferences 字段。
root@ser745692301841:/dev_dir/note# kubectl get pods
NAME READY STATUS RESTARTS AGE
avant-deployment-75f5fc4b49-4t8mc 1/1 Running 0 3h52m
avant-deployment-75f5fc4b49-gs4fl 1/1 Running 0 3h52m
avant-deployment-75f5fc4b49-hkpn7 1/1 Running 0 3h52m
root@ser745692301841:/dev_dir/note# kubectl get pods avant-deployment-75f5fc4b49-4t8mc -o=jsonpath='{.metadata.ownerReferences[0].name}'
avant-deployment-75f5fc4b49也可以确定 某个ReplicaSet 管理了哪些Pod。
使用 kubectl describe 命令获取该 ReplicaSet 的 标签选择器(label selector)。
要找到与这个选择器匹配的 Pod,可以使用 --selector
参数,或者它的简写 -l:
$ kubectl get pods -l app=kuard,version=2通过修改Kubernetes中存储的ReplicaSet对象里的
spec.replicas 字段进行扩缩容。
$ kubectl scale replicasets kuard --replicas=4命令式在演示场景 或 需要快速应对紧急情况,例如服务负载突然增加时非常有用。
同样重要的一点:你还需要更新任何文本配置文件,使其与通过命令式 scale 命令设置的副本数量保持一致。
例如生产环境:Alice值班,发现服务负载大幅增加,使用 sacle 命令 扩容,但忘记同步到源码仓库中的 ReplicaSet配置文件。
Bob正准备每周的发布rollout,Bob 编辑版本控制中的 ReplicaSet 配置文件,准备使用新的容器镜像。但他没有注意到配置文件中的副本数目前是 5,而不是 Alice 为应对高负载所设置的 10。
Bob继续发布,这个过程不仅更新了容器镜像,还将副本数减少了一半。服务立刻出现过载,并最终导致一次系统宕机(outage)。
“任何通过命令式方式做出的修改,都应该立即在源码中的声明式配置里同步更新”
| 概念 | 含义 |
|---|---|
| Imperative(命令式) | 直接用命令修改集群状态,例如 kubectl scale |
| Declarative(声明式) | 修改 YAML 配置并 kubectl apply |
| 风险 | 命令式修改不会自动更新代码仓库配置 |
| 推荐实践 | 紧急情况可用命令式,但必须同步更新 YAML |
集群状态必须和Git中的配置保持一致,否则迟早出事故。
在声明式(Declarative)的世界里,你不是直接下命令去改变系统状态,而是修改配置文件,然后把这个配置重新应用到集群中。
修改,kuard-rs.yaml ,在多人协作环境,这种修改通常会代码评审(code review),提交到 Github、Gitlab。
修改后,可以使用 kubectl apply
$ kubectl apply -f kuard-rs.yaml
replicaset "kuard" configured但很多情况下,只是希望拥有“足够多”的副本即可
“足够多”取决于ReplicaSet中容器的需求,例如
Kubernetes 可以通过 Horizontal Pod Autoscaler(HPA) 来处理所有这些场景。
Kubernetes区分了两种扩容方式:
一些解决方案还支持 集群自动扩缩容(Cluster Autoscaling),即根据资源需求自动增加或减少集群中的机器数量。
自动扩缩容需要你的集群中存在 metrics-server(大多数Kubernetes安装默认都会包含)。
metrics-server负责:
root@ser745692301841:/dev_dir/note# kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
coredns-7d764666f9-fhv7p 1/1 Running 0 4h16m
coredns-7d764666f9-x6vrq 1/1 Running 0 4h16m
etcd-kind-control-plane 1/1 Running 0 4h16m
kindnet-8zbfd 1/1 Running 0 4h16m
kindnet-dtrnr 1/1 Running 0 4h16m
kindnet-nm4qw 1/1 Running 0 4h16m
kube-apiserver-kind-control-plane 1/1 Running 0 4h16m
kube-controller-manager-kind-control-plane 1/1 Running 0 4h16m
kube-proxy-4pt8h 1/1 Running 0 4h16m
kube-proxy-lr9m4 1/1 Running 0 4h16m
kube-proxy-rn97g 1/1 Running 0 4h16m
kube-scheduler-kind-control-plane 1/1 Running 0 4h16m
root@ser745692301841:/dev_dir/note# kubectl top nodes
error: Metrics API not available
root@ser745692301841:/dev_dir/note# kubectl top pods
error: Metrics API not available找不到 metrics-server 就得自己安装。
基于CPU的自动扩缩容,根据CPU使用率进行自动扩缩容是最常见的用例。
kubectl autoscale rs kuard --min=2 --max=5 --cpu-percent=80这个命令会创建一个 自动扩缩容器(autoscaler),规则是
当 CPU 使用率超过 80% 时,系统会增加 Pod 副本;当使用率下降时,会减少副本。
要查看、修改或删除这个资源,可以使用 kubectl 的标准命令,并操作 horizontalpodautoscalers 资源。
kubectl get hpa不要同时使用自动扩缩容和手动(命令式或声明式)方式来管理副本数量
$ kubectl delete rs kuard
replicaset "kuard" deleted
$ kubectl get pods删除 ReplicaSet ,其创建的所有Pod也会被删除。
如果不想删除 ReplicaSet 所管理的Pod,可以将
--cascade=false
$ kubectl delete rs kuard --cascade=false使用 ReplicaSet 组合 Pod,为构建具有 自动故障恢复能力的健壮应用提供了基础。同时,它也使应用部署变得非常简单,因为它支持 可扩展且合理的部署模式。
只要是你在意的 Pod,都应该使用 ReplicaSet 来管理,即使只有 一个 Pod 也是如此!
有些人甚至默认 优先使用 ReplicaSet,而不是直接创建 Pod。
在一个典型的 Kubernetes 集群中,通常会存在 大量的 ReplicaSet,因此可以在需要的地方 广泛地使用它们。
目前位置,经过前面学习,你已经了解了
Deployment 对象的存在是为了解决新版本发布的管理问题。可以做到不停机进行版本更新,滚动发布 rollout。
和其他Kubernetes对象一样,Deployment也可以用声明式YAML文件来描述希望运行的内容。
kuard-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kuard
labels:
run: kuard
spec:
selector:
matchLabels:
run: kuard
replicas: 1
template:
metadata:
labels:
run: kuard
spec:
containers:
- name: kuard
image: gcr.io/kuar-demo/kuard-amd64:blue使用命令创建Deployment
$ kubectl create -f kuard-deployment.yamlDeployment管理ReplicaSets,ReplicaSet管理Pods,关系都是通过 标签 和 标签选择器 定义的。
$ kubectl get deployments kuard -o jsonpath --template {.spec.selector.matchLabels}
{"run":"kuard"}
$ kubectl get replicasets --selector=run=kuard
NAME DESIRED CURRENT READY AGE
kuard-1128242161 1 1 1 13m可以看到,Deployment正在管理一个标签 run=kuard
的ReplicaSet
Deployment和ReplicaSet的关系
可以使用命令式缩容调整Deployment
$ kubectl scale deployments kuard --replicas=2
deployment.apps/kuard scaled
$ kubectl get replicasets --selector=run=kuard
NAME DESIRED CURRENT READY AGE
kuard-1128242161 2 2 2 13m也可以直接扩缩容ReplicaSet
$ kubectl scale replicasets kuard-1128242161 --replicas=1
replicaset.apps/kuard-1128242161 scaled
$ kubectl get replicasets --selector=run=kuard
NAME DESIRED CURRENT READY AGE
kuard-1128242161 2 2 2 13m直接把ReplicaSet缩容到1个副本,但它的desired状态仍为2,Kubernets是一个在线自愈系统,
顶层的Deployment对象正在管理这个 ReplicaSet,当只修改
ReplicaSet的副本数,使得 Deploymenbt的 replicas: 2
不匹配,Deployment 控制器会把它自动调整为 2。
直接管理ReplicaSet
先把上层Deployment删除,不然它会自愈。删除对应 Deployment 使用
--cascade=false , 否则连同 ReplicaSet 和 Pods
一起被删除。
应该优先选择声明式管理Kubernetes配置,可以将现有Deployment下载成YAML
$ kubectl get deployments kuard -o yaml > kuard-deployment.yaml
$ kubectl replace -f kuard-deployment.yaml --save-configkubectl replace --save-config
会添加一个注解,以便未来应用更改时,kubectl 能知道上一次应用的配置。
kuard-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: null
generation: 1
labels:
run: kuard
name: kuard
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
run: kuard
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
run: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: IfNotPresent
name: kuard
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status: {}stratey决定了版本发布的不同方式,Deployment支持 Recreate 和 RollingUpdate。
可以通过 describe 命令获取 Deployment 的详细信息。
$ kubectl describe deployments kuard
Name: kuard
Namespace: default
CreationTimestamp: Tue, 01 Jun 2021 21:19:46 -0700
Labels: run=kuard
Annotations: deployment.kubernetes.io/revision: 1
Selector: run=kuard
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 ...
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: run=kuard
Containers:
kuard: Image: gcr.io/kuar-demo/kuard-amd64:blue
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: kuard-6d69d9fc5c (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 4m6s deployment-con... ...
Normal ScalingReplicaSet 113s (x2 over 3m20s) deployment-con... ...两个关键字段是,OldReplicaSets 和 NewReplicaSet,如果Deployment正在
进行滚动更新,两个字段都会有值;如果滚动更新完成,OldReplicaSets会 显示
<none。
查看某个Deployment的历史滚动记录
kubectl rollout history deployments deploymentName查看当前滚动状态
kubectl rollout status deployments deploymentNameDeployment是描述已部署应用的声明式对象。最常见两种操作是 扩缩容 和 应用更新。
编辑YAML文件,将副本数修改
...
spec:
replicas: 3
...保存并提交修改后,使用 apply 命令更新 Deployment
$ kubectl apply -f kuard-deployment.yaml会更新Deployment的期望状态,使其管理的ReplicaSet副本数量变动,进而影响Pods的数量。
$ kubectl get deployments kuard
NAME READY UP-TO-DATE AVAILABLE AGE
kuard 3/3 3 3 10m更新Deployment的常见场景是为一个或多个容器推出新版本的软件。 需要编辑Deployment的YAML文件,修改容器镜像
...
containers:
- image: gcr.io/kuar-demo/kuard-amd64:green
imagePullPolicy: Always
...为 Deployment 的模板添加注解,用于记录此次更新的信息:
spec:
...
template:
metadata:
annotations:
kubernetes.io/change-cause: "Update to green kuard"
...在简单的扩缩容操作时不要更新注解,修改这个注解属于模板重大变更,会触发新的滚动更新。
$ kubectl apply -f kuard-deployment.yaml更新Deployment后,触发一次滚动更新,可以使用命令进行监控
$ kubectl rollout status deployments kuard
deployment "kuard" successfully rolled out可以查看Deployment管理的旧的和新的ReplicaSet以及它们使用的镜像, 旧的ReplicaSet会保留,以便在回滚时使用。
$ kubectl get replicasets -o wide
NAME DESIRED CURRENT READY ... IMAGE(S) ...
kuard-1128242161 0 0 0 ... gcr.io/kuar-demo/ ...
kuard-1128635377 3 3 3 ... gcr.io/kuar-demo/ ...如果在滚动更新过程中想暂停,例如系统出现异常行为,需要排查,可以使用pause命令
$ kubectl rollout pause deployments kuard
deployment.apps/kuard paused
# 排查完问题,确认可以继续滚动更新,使用resume继续之前的进度
$ kubectl rollout resume deployments kuard
deployment.apps/kuard resumedKubernetes的Deployment会维护一次滚动更新的历史记录,对了解Deployment之前状态 或者回滚到特定版本非常有用。
# 查看Deployment的历史记录
$ kubectl rollout history deployment kuard
deployment.apps/kuard
REVISION CHANGE-CAUSE
1 <none>
2 Update to green kuard查看某个特定版本的详细信息
$ kubectl rollout history deployment kuard --revision=2
deployment.apps/kuard with revision #2
Pod Template:
Labels: pod-template-hash=54b74ddcd4
run=kuard
Annotations: kubernetes.io/change-cause: Update to green kuard
Containers:
kuard:
Image: gcr.io/kuar-demo/kuard-amd64:green
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>加上把kuard镜像再改回blue并更新 change-cause
注解,然后应用
$ kubectl apply -f kuard-deployment.yaml
$ kubectl rollout history deployment kuard
deployment.apps/kuard
REVISION CHANGE-CAUSE
1 <none>
2 Update to green kuard
3 Update to blue kuard回滚操作
如果新版本有问题,需要回滚,可以使用
$ kubectl rollout undo deployments kuard
deployment.apps/kuard rolled back
$ kubectl get replicasets -o wide
NAME DESIRED CURRENT READY ... IMAGE(S)
kuard-1128242161 0 0 0 ... gcr.io/kuar-demo/...
kuard-1570155864 0 0 0 ... gcr.io/kuar-demo/...
kuard-2738859366 3 3 3 ... gcr.io/kuar-demo/...回滚到指定版本
回滚后原来的版本号会被重新编号
deployment.apps/kuard
REVISION CHANGE-CAUSE
1 <none>
3 Update to blue kuard
4 Update to green kuard可以回滚到特定版本
$ kubectl rollout undo deployments kuard --to-revision=3
deployment.apps/kuard rolled back
$ kubectl rollout history deployment kuard
deployment.apps/kuard
REVISION CHANGE-CAUSE
1 <none>
4 Update to green kuard
5 Update to blue kuard
# --to-revision=0 等同于回滚到上一个版本限制历史版本数量
默认情况下,Deployment会保留最新10个版本,可以再Deployment配置中设置
spec:
# 我们每天更新,限制历史版本为两周的更新记录
revisionHistoryLimit: 14需要更改实现服务的软件版本时,Kubernetes的Deployment支持两种不同的 发布 rollout 策略:Recreate和RollingUpdate。
Recreate策略,重建策略,其工作方式非常直接:
把所管理的ReplicaSet更新为使用新的镜像,然后终止删除所有与该Deployment关联的Pod。
接着 ReplicaSet 会发现自己已经没有任何副本(replicas)了,于是会重新创建所有 Pod,并使用新的镜像。
虽然这种策略简单而执行速度快,但它会导致服务出现停机。
可以在服务仍然接收用户流量的情况下发布新版本,而不会产生停机时间。
一次只更新少量Pod,逐步向前推进,知道所有Pod都运行新的软件版本为止。
当在 滚动更新(RollingUpdate)时,系统有一段时间同时运行 新版本 和 旧版本。
服务 新旧版本都会同时接收请求并处理流量,这对软件的设计方式有非常重要影响。
“你的每一个软件版本,以及使用它的客户端,都必须能够同时与稍旧版本和稍新版本正常通信。”
这要求,版本之间必须具备 向前兼容(forward compatibility) 和 向后兼容(backward compatibility)
t0 用户发起请求
-> 被版本1服务器处理
t1 你开始更新服务
-> 系统升级到版本2
t2 用户浏览器中的旧客户端代码再次调用 API
-> 访问到版本2服务器
出现 版本1客户端 → 调用 → 版本2服务器总之,滚动更新会意味着 系统会短暂同时运行多个版本,需要保证 向前兼容 和 向后兼容。
这不是
Kubernetes的问题,这是软件工程实现的一部分,哪怕HTTP接口有些工程里也会使用
/api/v1 和 /api/v2 这样的Path。
有两个参数,可以用来调节滚动更新的行为
maxUnavailable参数
maxUnavailable 参数用于设置在滚动更新过程中,最多允许多少个 Pod 不可用。
从本质上,maxUnavailable 控制的是滚动更新推进的速度。
RollingUpdate + maxUnavailable = 100%如果配50%,滚动更新上来就会砍一半旧的Pods,然后加一半新的Pods。
maxSurge参数
有时你不希望服务容量低于 100%,但愿意临时使用更多资源完成更新。这时可以
maxUnavailable = 0然后通过maxSyrge控制更新。
maxSurge也可以设置为,具体数量,百分比,它控制的是 “在滚动更新期间最多可以额外创建多少个 Pod。”
例如配 20%,滚动更新上来会创建 20%新版本的Pods,老版本先不动,然后再砍老 版本Pods,加新版本Pods。
分阶段发布(Staged rollout)的目的是确保在发布过程中,最终运行的是一个健康、稳定的新版本服务。
Deployment控制器在更新过程中始终遵循着,
“只有一个Pod报告自己Ready就绪后,才会继续更新下一个Pod”
就绪Ready,是通过readiness check确定的。
如果希望使用 Deployment 可靠地发布软件,就必须为Pod地容器配置 health check。
有时仅仅Pod变Ready还不够,因为有些错误不会立即出现。在大多数真实生产环境中,你通常希望:在更新下一个 Pod 之前,等待一段时间,以确保新版本运行正常。
设置等待时间
在 Deployment 中,这个等待时间由参数 minReadySeconds 控制:
spec:
minReadySeconds: 60Deployment 在检测到 Pod 变为健康之后,必须再等待 60 秒,才会继续更新下一个 Pod。
设置发布超时
除了等待Pod变为健康之外,还需要设置一个超时时间,假设你的新版本服务有 bug,并且一启动就死锁。
Pod永远不会变成Ready,Deployment控制器会无限等待,整个发布流程永远卡住。
正确行为应该是,发布超时并标记发布失败。Deployment进入failed状态,触发告警系统,通知运维人员发布失败。
spec:
progressDeadlineSeconds: 600发布的某个阶段,如果10分钟内没有任何进展,Deployment会被标记为失败。所有继续推进 Deployment 的操作都会被停止。
$ kubectl delete deployments kuard也可以使用之前创建的 声明式YAML文件来删除
$ kubectl delete -f kuard-deployment.yaml只删除Deployment,不删除ReplicaSet和Pods
$ kubectl delete deployments kuard --cascade=false如果一个 Deployment 在指定时间内没有取得进展,它就会 超时(timeout)。 一旦发生这种情况,Deployment 的状态会变为 失败(failed)。
这个状态可以从 status.conditions 数组
中获取。在该数组里会存在一个:
当 Deployment 处于这种状态时,说明 部署已经失败,并且不会继续推进。
Kubernetes的主要目标是能够容易地构建和部署 可靠的分布式系统。
不仅仅,只把应用启动一次。更重要的是 持续管理软件服务的新版本发布,定期滚动更新应用。
Deployment 是实现 可靠发布(reliable rollout) 和 发布管理(rollout management) 的关键组件。
Deployments和ReplicaSets通常用于创建服务,通过运行多个副本实现冗余。
另一种常见的需求是:在集群的每个节点上运行一个Pod。实现这种功能的资源对象是 DaemonSet。
DaemonSets确保在kubernets集群的一组节点上运行一个Pod副本。通常用于部署系统级守护进程,例如
可以通过标签控制 DaemonSet 只在某些节点运行。
DaemonSet还可以用来 在云环境的集群节点上安装软件,通过每个节点都用 DaemonSet运行某个Pod,间接达到
默认情况,DaemonSet会在集群中的每一个节点上创建一个Pod副本。
除非你使用了 node selector(节点选择器),否则所有节点都会被认为是可运行该 Pod 的节点。节点选择器可以通过匹配节点标签来限制可运行 Pod 的节点范围。
DaemonSet 在 创建 Pod 时 就会决定 Pod 应该运行在哪个节点上,它通过在 Pod 的 spec 中指定 nodeName 字段 来实现这一点。
“由DaemonSet创建的Pod会被Kubernetes调度器忽略”
和ReplicaSet一样,DaemonSet也是通过 协调控制循环 来进行管理。
| 控制器 | 调度方式 |
|---|---|
| ReplicaSet | 交给 Scheduler |
| DaemonSet | 自己指定 nodeName |
DaemonSet 通过向 Kubernetes API Server 提交一个 DaemonSet 配置来创建。
例如 在目标集群的每个节点上创建一个fluentd日志代理。
fluentd.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
containers:
- name: fluentd
image: fluent/fluentd:v0.14.10
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers创建DaemonSet,可以使用 apply
kubectl apply -f fluentd.yaml
daemonset.apps/fluentd created可以用 describe
kubectl describe daemonset fluentd
Name: fluentd
Selector: app=fluentd
Node-Selector: <none>
Labels: app=fluentd
Annotations: deprecated.daemonset.template.generation: 1
Desired Number of Nodes Scheduled: 3
Current Number of Nodes Scheduled: 3
Number of Nodes Scheduled with Up-to-date Pods: 3
Number of Nodes Scheduled with Available Pods: 3
Number of Nodes Misscheduled: 0
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
...上面例子,集群中有3个节点,每个节点都成功运行了一个fluentd Pod
kubectl get pods -l app=fluentd -o wide
NAME READY STATUS RESTARTS AGE IP NODE
fluentd-1q6c6 1/1 Running 0 13m 10.240.0.101 k0-default...
fluentd-mwi7h 1/1 Running 0 13m 10.240.0.80 k0-default...
fluentd-zr6l7 1/1 Running 0 13m 10.240.0.44 k0-default...可见,每个Pod被调度到了不同的Node上。
如果集群新增一个节点,DaemonSet会自动在新节点上创建Pod。
| 控制器 | 行为 |
|---|---|
| Deployment / ReplicaSet | 控制 Pod 数量 |
| DaemonSet | 控制 Pod 每个节点一个 |
可以通过 节点标签(node labels) 来标记满足条件的节点,然后让 DaemonSet 只调度到这些节点上运行。
给节点打标签 → DaemonSet 只跑到带这个标签的节点上。
node1 gpu=true
node2 gpu=true
node3 gpu=false
# DaemonSet配置
nodeSelector:
gpu: "true"
# 结果就是 node1 node2 有Pod,node3上不创建例如给一个节点添加 ssd=true 标签
$ kubectl label nodes k0-default-pool-35609c18-z7tb ssd=true
node/k0-default-pool-35609c18-z7tb labeled
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k0-default-pool-35609c18-0xnl Ready agent 23m v1.21.1
k0-default-pool-35609c18-pol3 Ready agent 1d v1.21.1
k0-default-pool-35609c18-ydae Ready agent 1d v1.21.1
k0-default-pool-35609c18-z7tb Ready agent 1d v1.21.1
$ kubectl get nodes --selector ssd=true
NAME STATUS ROLES AGE VERSION
k0-default-pool-35609c18-z7tb Ready agent 1d v1.21.1Node Selector 可以用来限制 Pod 在 Kubernetes 集群中只能运行在特定节点上。 在创建 DaemonSet 时,可以在 Pod 的 spec 中定义 nodeSelector。
nginx-fast-storage.yaml
apiVersion: apps/v1
kind: "DaemonSet"
metadata:
labels:
app: nginx
ssd: "true"
name: nginx-fast-storage
spec:
selector:
matchLabels:
app: nginx
ssd: "true"
template:
metadata:
labels:
app: nginx
ssd: "true"
spec:
nodeSelector:
ssd: "true"
containers:
- name: nginx
image: nginx:1.10.0只在有 ssd=true 标签的节点上运行一个Pod。
kubectl apply -f nginx-fast-storage.yaml
daemonset.apps/nginx-fast-storage created
kubectl get pods -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-fast-storage-7b90t 1/1 Running 0 44s 10.240.0.48 ...如果临时给更多节点添加 ssd=true 标签
kubectl label nodes node2 ssd=trueDaemonSet会自动在这些节点上部署新的Pod。反过来移除节点上的标签
kubectl label nodes node2 ssd-DaemonSet控制器会把该节点上的Pod删除。
从 Kubernetes 1.6 开始,DaemonSet 获得了类似 Deployment 的更新能力,可以在集群中执行 滚动更新(rolling rollout)。以前旧版本需要 先更新DaemonSet配置 然后手动删除每个Pod DaemonSet自动创建新Pod。
DaemonSet 可以使用与 Deployment 相同的 RollingUpdate 策略进行发布。
通过字段
spec.updateStrategy.type
# 设置为
RollingUpdate当 DaemonSet 使用 RollingUpdate 策略时,只要 spec.template 字段(或其子字段)发生变化,就会触发一次滚动更新。
与 Deployment 的滚动更新类似,RollingUpdate 会逐步更新 DaemonSet 中的 Pod,直到所有 Pod 都运行新配置。
spec.minReadySeconds 一个 Pod
在被认为“就绪(ready)”之后,需要保持多久,滚动更新才会继续更新下一个
Pod。
spec.updateStrategy.rollingUpdate.maxUnavailable
在滚动更新过程中,最多允许多少个 Pod 同时不可用。
一旦滚动更新开始,可以使用 kubectl rollout 命令查看当前状态。
# 该命令会显示 名为 my-daemon-set 的 DaemonSet 当前滚动更新的状态
kubectl rollout status daemonsets my-daemon-set$ kubectl delete -f fluentd.yaml如果你希望 只删除 DaemonSet,而保留这些 Pod
$ kubectl delete -f fluentd.yaml --cascade=falseDeployment:我要 N 个副本,在哪跑无所谓。
DaemonSet:每个节点必须跑一个,不跑不行。
一个是“数量驱动”,一个是“节点驱动”。
可能需要运行一些短声明周期的一次性任务,Job对象正式为处理这类任务而设计的。
一个Job会创建Pods,并让它们一直运行,知道执行结束。非常适合用于只需要执行一次的任务,如
| 类型 | 用途 |
|---|---|
| Job | 一次性任务 |
| Parallel Job | 并行批处理 |
| CronJob | 定时任务 |
Kubernetes把服务器当成大型Linux计划任务来用,把 crontab 升级成了“云原生版本”。
Job对象负责根据Job spec中的模板创建并管理Pod。
如果某个Pod在成功结束之前失败,Job控制器会根据Job spec中的Pod模板创建一个新的 Pod来重新执行任务。
极端故障场景,同一个任务可能会被创建出重复的Pod。
Kubernetes的设计哲学:“系统保证 至少执行一次,而不是 只执行一次”。写的Job程序里, 最好让任务具备 幂等性,不然重复执行就完蛋了。
Job被设计用来管理批处理类型的工作负载,这些任务会由一个或多个Pod来处理工作项。
默认,每个Job只会运行一个Pod,并且运行一次知道成功结束。
Job模式主要由两个关键参数决定:
| 类型 | 使用场景 | 行为 | completions | parallelism |
|---|---|---|---|---|
| 一次性任务(One shot) | 数据库迁移 | 一个 Pod 运行一次,直到成功结束 | 1 | 1 |
| 固定完成数并行任务(Parallel fixed completions) | 多个 Pod 并行处理一批任务 | 一个或多个 Pod 运行一次或多次,直到达到指定的完成数量 | 1+ | 1+ |
| 工作队列:并行任务(Work queue: parallel jobs) | 多个 Pod 从集中式工作队列中取任务处理 | 一个或多个 Pod 运行一次,直到成功结束 | 1 | 2+ |
一次性Job提供了一种运行单个Pod一次直至成功终止的方法。
最简单的方法是使用 kubectl 命令行工具:
# 启动一个 Pod,运行 kuard 程序生成 10 个密钥,生成完就退出。如果失败则自动重启
$ kubectl run -i oneshot \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--restart=OnFailure \
--command /kuard \
-- --keygen-enable \
--keygen-exit-on-complete \
--keygen-num-to-gen 10
...
(ID 0) Workload starting
(ID 0 1/10) Item done: SHA256:nAsUsG54XoKRkJwyN+OShkUPKew3mwq7OCc
(ID 0 2/10) Item done: SHA256:HVKX1ANns6SgF/er1lyo+ZCdnB8geFGt0/8
(ID 0 3/10) Item done: SHA256:irjCLRov3mTT0P0JfsvUyhKRQ1TdGR8H1jg
(ID 0 4/10) Item done: SHA256:nbQAIVY/yrhmEGk3Ui2sAHuxb/o6mYO0qRk
(ID 0 5/10) Item done: SHA256:CCpBoXNlXOMQvR2v38yqimXGAa/w2Tym+aI
(ID 0 6/10) Item done: SHA256:wEY2TTIDz4ATjcr1iimxavCzZzNjRmbOQp8
(ID 0 7/10) Item done: SHA256:t3JSrCt7sQweBgqG5CrbMoBulwk4lfDWiTI
(ID 0 8/10) Item done: SHA256:E84/Vze7KKyjCh9OZh02MkXJGoty9PhaCec
(ID 0 9/10) Item done: SHA256:UOmYex79qqbI1MhcIfG4hDnGKonlsij2k3s
(ID 0 10/10) Item done: SHA256:WCR8wIGOFag84Bsa8f/9QHuKqF+0mEnCADY
(ID 0) Workload exiting-i
选项是表示这是一条交互式命令,kubectl等待任务运行,然后显示出任务第一个Pod(本例中也只有一个Pod)的日志输出--restart=OnFailure,Pod的重启策略,Always
一直重启,OnFailure 失败才重启,Never 不重启-- 后面的所有选项会在运行 command 是添加除非通过 -a 标志,否则Job不会显示在
kubectl get jobs 中,没有加 -a
kubectl会隐藏已完成的Job。
# 删除Job
$ kubectl delete pods oneshot创建一次性任务的另一种方法是使用配置文件
job-oneshot.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: oneshot
spec:
template:
spec:
containers:
- name: kuard
image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: Always
command:
- "/kuard"
args:
- "--keygen-enable"
- "--keygen-exit-on-complete"
- "--keygen-num-to-gen=10"
restartPolicy: OnFailure使用 kubectl apply 命令提交任务:
$ kubectl apply -f job-oneshot.yaml
job.batch/oneshot created使用 describe
$ kubectl describe jobs oneshot
Name: oneshot
Namespace: default
Selector: controller-uid=a2ed65c4-cfda-43c8-bb4a-707c4ed29143
Labels: controller-uid=a2ed65c4-cfda-43c8-bb4a-707c4ed29143
job-name=oneshot
Annotations: <none>
Parallelism: 1
Completions: 1
Start Time: Wed, 02 Jun 2021 21:23:23 -0700
Completed At: Wed, 02 Jun 2021 21:23:51 -0700
Duration: 28s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=a2ed65c4-cfda-43c8-bb4a-707c4ed29143
job-name=oneshot
Events:
... Reason Message
... ------ -------
... SuccessfulCreate Created pod: oneshot-4kfdt上面 自动为Pod添加了标签,Job对象会自动选择一个唯一标签,并用它来表示所创建的Pod。
可以通过查看创建的Pod的日志来查看Job的结果
$ kubectl logs oneshot-4kfdt
...
Serving on :8080
(ID 0) Workload starting
(ID 0 1/10) Item done: SHA256:+r6b4W81DbEjxMcD3LHjU+EIGnLEzbpxITKn8IqhkPI
(ID 0 2/10) Item done: SHA256:mzHewajaY1KA8VluSLOnNMk9fDE5zdn7vvBS5Ne8AxM
(ID 0 3/10) Item done: SHA256:TRtEQHfflJmwkqnNyGgQm/IvXNykSBIg8c03h0g3onE
(ID 0 4/10) Item done: SHA256:tSwPYH/J347il/mgqTxRRdeZcOazEtgZlA8A3/HWbro
(ID 0 5/10) Item done: SHA256:IP8XtguJ6GbWwLHqjKecVfdS96B17nnO21I/TNc1j9k
(ID 0 6/10) Item done: SHA256:ZfNxdQvuST/6ZzEVkyxdRG98p73c/5TM99SEbPeRWfc
(ID 0 7/10) Item done: SHA256:tH+CNl/IUl/HUuKdMsq2XEmDQ8oAvmhMO6Iwj8ZEOj0
(ID 0 8/10) Item done: SHA256:3GfsUaALVEHQcGNLBOu4Qd1zqqqJ8j738i5r+I5XwVI
(ID 0 9/10) Item done: SHA256:5wV4L/xEiHSJXwLUT2fHf0SCKM2g3XH3sVtNbgskCXw
(ID 0 10/10) Item done: SHA256:bPqqOonwSbjzLqe9ZuVRmZkz+DBjaNTZ9HwmQhbdWLI
(ID 0) Workload exiting例如修改配置文件,使其生成三个密钥后以非零退出码失败
job-oneshot-failure1.yaml
...
spec:
template:
spec:
containers:
...
args:
- "--keygen-enable"
- "--keygen-exit-on-complete"
- "--keygen-exit-code=1"
- "--keygen-num-to-gen=3"
...apply创建Job
$ kubectl apply -f job-oneshot-failure1.yaml
# 运行一段时间后
$ kubectl get pod -l job-name=oneshot
NAME READY STATUS RESTARTS AGE
oneshot-3ddk0 0/1 CrashLoopBackOff 4 3m
$ kubectl delete jobs oneshot可见Pod已经重启了四次。
如果将 restartPolicy 从 OnFailure 改为 Never
# 将 restartPolicy改为Never
$ kubectl apply -f jobs-oneshot-failure2.yaml
# 运行一段时间
$ kubectl get pod -l job-name=oneshot -a
NAME READY STATUS RESTARTS AGE
oneshot-0wm49 0/1 Error 0 1m
oneshot-6h9s2 0/1 Error 0 39s
oneshot-hkzw0 1/1 Running 0 6s
oneshot-k5swz 0/1 Error 0 28s
oneshot-m1rdw 0/1 Error 0 19s
oneshot-x157b 0/1 Error 0 57s设置 restartPolicy: Never,告诉 kubelet
在Pod出现出现故障时不要重启Pod,而是直接宣布 Pod故障,然后 Job
对象会注意到并创建一个替代Pod。不小心会在集群中产生大量“垃圾”。
还有其他情况,就是程序卡住了,而不是退出码问题,可以使用 liveness probe 解决,liveness prob 策略确定Pod已死亡,Pod将会被重启或替换。
结合 completions 和 parallelism 参数,可以启动多个程序任务。
job-parallel.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: parallel
labels:
chapter: jobs
spec:
parallelism: 5
completions: 10
template:
metadata:
labels:
chapter: jobs
spec:
containers:
- name: kuard
image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: Always
command:
- "/kuard"
args:
- "--keygen-enable"
- "--keygen-exit-on-complete"
- "--keygen-num-to-gen=10"
restartPolicy: OnFailureapply启动
$ kubectl apply -f job-parallel.yaml
job.batch/parallel created$ kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
parallel-55tlv 1/1 Running 0 5s
parallel-5s7s9 1/1 Running 0 5s
parallel-jp7bj 1/1 Running 0 5s
parallel-lssmn 1/1 Running 0 5s
parallel-qxcxp 1/1 Running 0 5s
NAME READY STATUS RESTARTS AGE
parallel-jp7bj 0/1 Completed 0 26s
parallel-tzp9n 0/1 Pending 0 0s
parallel-tzp9n 0/1 Pending 0 0s
parallel-tzp9n 0/1 ContainerCreating 0 1s
parallel-tzp9n 1/1 Running 0 1s
parallel-tzp9n 0/1 Completed 0 48s
parallel-x1kmr 0/1 Pending 0 0s
...
$ kubectl delete job parallel使用
-w,可看出变化,新的Pod会不断创建,知道10个Pod全部完成。
可能想安排一个Job在某个时间间隔运行。
可以在 Kubernetes 中声明一个 CronJob,它负责在特定时间间隔创建一个新的作业对象。
job-cronjob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: example-cron
spec:
# Run every fifth hour
schedule: "0 */5 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: batch-job
image: my-batch-image
restartPolicy: OnFailure其中 spec.schedule 字段,其中包含标准 cron
格式的CronJob时间间隔。
# 创建CronJob
$ kubectl create -f cron-job.yaml
# 使用describe查看详细信息
kubectl describe <cron-job>ConfigMaps用于为工作负载提供配置信息。
Secrets与ConfigMaps类似,但侧重于向工作负载提供敏感信息,可用于凭证或TLS证书等。
理解ConfigMap的一种方式,把它看成Kubernetes对象,用来定义一个小型文件系统。另一种理解方式, 吧它堪称一组变量,这些变量可以定义容器的环境变量或命令行参数时使用。
ConfigMap会在Pod运行之前与Pod进行组合。
my-config.txt
# This is a sample config file that I might use to configure an application
parameter1 = value1
parameter2 = value2使用这个文件创建一个 COnfigMap,同时在添加几个简单的 键值对,这些在命令行中被称为 literal values 字面值
kubectl create configmap my-config \
--from-file=my-config.txt \
--from-literal=extra-param=extra-value \
--from-literal=another-param=another-value输出YAML 表示
kubectl get configmaps my-config -o yamlapiVersion: v1
data:
another-param: another-value
extra-param: extra-value
my-config.txt: |
# This is a sample config file that I might use to configure an application
parameter1 = value1
parameter2 = value2
kind: ConfigMap
metadata:
creationTimestamp: ...
name: my-config
namespace: default
resourceVersion: "13556"
selfLink: /api/v1/namespaces/default/configmaps/my-config
uid: 3641c553-f7de-11e6-98c9-06135271a273ConfigMap 本质只是一个对象里存储的一组 键值对。文件被当成一个key 内容作为value存进去。
使用ConfigMap主要有三种方式
kuard-conig.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard-config
spec:
containers:
- name: test-container
image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: Always
command:
- "/kuard"
- "$(EXTRA_PARAM)"
env:
# 在容器内部使用的环境变量示例
- name: ANOTHER_PARAM
valueFrom:
configMapKeyRef:
name: my-config
key: another-param
# 传递给容器启动命令(上面)的环境变量示例
- name: EXTRA_PARAM
valueFrom:
configMapKeyRef:
name: my-config
key: extra-param
volumeMounts:
# 将 ConfigMap 挂载为一组文件
- name: config-volume
mountPath: /config
volumes:
- name: config-volume
configMap:
name: my-config
restartPolicy: Never上面的
定义了环境变量值来源于指定的ConfigMap,把ConfigMap挂载为一组文件在
/config 下。
$ kubectl apply -f kuard-config.yamlKubernetes为存储和处理敏感数据如 密码、安全令牌、私钥 提供了原生支持。
Secret的主要作用是让 容器镜像在构建时不需要包含敏感数据。
默认情况下,Kubernetes的Secrets会以明文形式存储在集群的etcd数据库中。
在较新的 Kubernetes 版本中,已经加入了一些更安全的机制:
| 类型 | 作用 |
|---|---|
| ConfigMap | 存普通配置 |
| Secret | 存敏感数据 |
Secret 用来存储一个或多个数据元素,这些数据以 键值对(key/value) 的形式保存。
下面例子 将创建一个Secret,用来存储应用的TLS私钥和证书,以满足前面提到的存储要求。
kubectl create secret generic kuard-tls \
--from-file=kuard.crt \
--from-file=kuard.key| 参数 | 作用 |
|---|---|
| create secret | 创建 Secret |
| generic | 通用类型 Secret |
| kuard-tls | Secret 名字 |
| –from-file | 从文件读取数据 |
$ kubectl describe secrets kuard-tls
Name: kuard-tls
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
kuard.crt: 1050 bytes
kuard.key: 1679 bytesSecret类型
Type: Opaque
# 表示普通二进制Secret类型| 类型 | 用途 |
|---|---|
| Opaque | 通用 Secret |
| kubernetes.io/tls | TLS证书 |
| kubernetes.io/dockerconfigjson | Docker registry 登录信息 |
| kubernetes.io/service-account-token | ServiceAccount token |
可以通过Secrets Volume把Secret暴露给Pod。
如果 Secret kuard-tls 挂载到 /tls
容器里就会看到,应用程序只需要像普通文件一样读取证书。
/tls/kuard.crt
/tls/kuard.keykuard-secret.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard-tls
spec:
containers:
- name: kuard-tls
image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: Always
volumeMounts:
- name: tls-certs
mountPath: "/tls"
readOnly: true
volumes:
- name: tls-certs
secret:
secretName: kuard-tls创建Pod
$ kubectl apply -f kuard-secret.yamlSecrets的一个特殊用途是用来存储访问私有容器镜像仓库的凭据。
Kubernetes 提供了 Image Pull Secrets。创建 Image Pull Secret
kubectl create secret docker-registry my-image-pull-secret \
--docker-username=<username> \
--docker-password=<password> \
--docker-email=<email-address>这个命令会创建一个Secret,其中包含
在Pod的manifest文件中引用这个Secret
kuard-secret-ips.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard-tls
spec:
containers:
- name: kuard-tls
image: gcr.io/kuar-demo/kuard-amd64:blue
imagePullPolicy: Always
volumeMounts:
- name: tls-certs
mountPath: "/tls"
readOnly: true
imagePullSecrets:
- name: my-image-pull-secret
volumes:
- name: tls-certs
secret:
secretName: kuard-tls这里的关键是
imagePullSecrets:
- name: my-image-pull-secret每个Pod都写一遍 imagePullSecrets 会很烦,Kubernetes提供了 把 Secret 添加到默认 ServiceAccount。
每个Pod自动继承不需要在每个Pod YAML里重复写。
在 Secret 或 ConfigMap 中,数据项的 key 名称需要满足可以映射为 合法环境变量名的规则。
规则
限制
key 名称必须符合下面的 正则表达式:
^[.]?[a-zAZ0-9]([.]?[a-zA-Z0-9]+[-_a-zA-Z0-9]?)*$| 合法 key 名称 | 非法 key 名称 |
|---|---|
.auth_token |
Token..properties 连续两个点 |
Key.pem |
auth file.json 包含空格 |
config_file |
_password.txt 以下划线开头 |
无论是 ConfigMap、Secret 它们的最大大小限制都是 1MB。
$ kubectl get secrets
NAME TYPE DATA AGE
default-token-f5jq2 kubernetes.io/service-account-token 3 1h
kuard-tls Opaque 2 20m$ kubectl get configmaps
NAME DATA AGE
my-config 3 1mdescribe 查看详情
$ kubectl describe configmap my-config
Name: my-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
another-param: 13 bytes
extra-param: 11 bytes
my-config.txt: 116 bytes现有的 configmap 或 secret 导出 YAML
$ kubectl get configmap my-config -o yaml
$ kubectl get secret kuard-tls -o yaml.$ kubectl create secret generic
$ kubectl create configmap有多种方式可以指定要存入 Secret 或 ConfigMap 的数据项,而且这些方式可以在 同一条命令中组合使用。
--from-file=<filename> 从指定文件加载数据,Secret
数据的 key 与文件名相同。--from-file=<key>=<filename>
从指定文件加载数据,并显式指定 Secret 数据的 key 名称。--from-file=<directory>
从指定目录加载数据。目录中的所有文件都会被读取,只要文件名是合法的 key
名称,就会作为一个数据项加入。--from-literal=<key>=<value> 直接使用指定的
key/value 键值对 作为数据。可以更新 ConfigMap 或 Secret,并让更新反映到正在运行的应用程序中。
如果应用应用程序被设计为能够重新读取配置值,那么就不需要重启应用。
如果已经为 ConfigMap 或 Secret 准备了 manifest,可以直接编辑文件,后使用命令
kubectl replace -f <filename>如果这个资源最初是通过 kubectl apply 创建的,那么也可以使用:
kubectl apply -f <filename>生成 YAML → 管道 → replace 覆盖原对象
$ kubectl create secret generic kuard-tls \
--from-file=kuard.crt --from-file=kuard.key \
--dry-run -o yaml | kubectl replace -f -本地重新创建命令输出YAML,重点
--dry-run,kubectl replace -f - 中的
-f - 表示,从标准输入读取YAML。
你会在编辑器中看到该 ConfigMap 的定义内容。进行你需要的修改,然后保存并关闭编辑器。
新的对象版本会被提交并更新到 Kubernetes API Server。
$ kubectl edit configmap my-config一旦通过 API 更新了 ConfigMap 或 Secret,新的数据会自动推送到所有使用该 ConfigMap 或 Secret 的 Volume 中。
应用程序可以看到,文件列表 和 文件内容 会被更新。
利用这种实时机制,可以实现 不重启应用的情况下更新应用的配置。
ConfigMap 和 Secret 是为应用程序提供动态配置的一种非常好的方式。
Role-Based Access Control 基于角色的访问控制
RBAC 提供了一种机制,用来限制:
目的很简单,确保只有被授权的人才能访问系统。比如,防止某个人在错误的namespace里,一不小心把 生产环境删了,还以为自己在删测试环境。
RBAC虽然限制 Kubernetes API 的访问很有用,但
只要有人能在集群里运行任意代码,他基本就能拿到整个集群的root权限。
如果你的目标是“多租户安全”(比如不信任的用户共享集群),光靠 RBAC 是不够的你还需要隔离 Pod,例如:
每一个发到 Kubernetes 的请求,都会经历两个阶段:
Kubernetes 的 RBAC 本质 “谁(User)能对什么(Resource)做什么(Verb)”
Kubernetes
中的每一个请求,都会关联一个身份,哪怕请求没有提供任何身份信息,
也会被归类到 system:unauthenticated 这个组里。
Kubernetes 有两种身份类型:
Kubernetes 使用一个通用的认证接口,不同的认证方式最终都会提供:
支持的认证方式包括:
Kubernetes 的身份系统核心就是:
“谁(identity)属于哪个组(group),然后你再决定他能干啥(RBAC)。”
说人话:
在Kubernetes中,有两队相关的资源用来表示“角色”和“角色绑定”。
Role(角色)
Role是命名空间内的权限定义,只在某一个namespace里生效。表示一组能力,仅局限于命名空间内。
Role示例(权限定义)
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-and-services
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["create", "delete", "get", "list", "patch", "update", "watch"]这个Role允许
RoleBinding(角色绑定)
RoleBinding 用来把某个Role绑定给某些身份(用户、用户组),只在命名空间内生效。
比如在default里绑定的权限,别幻想能跑去 kube-system 生效。
RoleBinding示例(权限分配)
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
namespace: default
name: pods-and-services
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: alice
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: mydevs
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: pod-and-services用 alice 和 mydevs,就可以在 default 命名空间里动 Pod 和 Service 了。
不想一个namespace一个namespace地配权限,就用 ClusterRole、ClusterRoleBinding
是集群级别的,可以 管理所有 namespace ,操作集群级资源如 Node、CRD。
| 类型 | 作用范围 |
|---|---|
| Role | 单个 namespace |
| ClusterRole | 整个集群 |
在 Kubernetes 中,Role 是由 资源 + 操作 共同定义的。
资源比如 Pods,而操作就是所谓的“动词”。
| 动词 | HTTP 方法 | 描述 |
|---|---|---|
| create | POST | 创建一个新的资源 |
| delete | DELETE | 删除一个已有资源 |
| get | GET | 获取单个资源 |
| list | GET | 获取资源列表 |
| patch | PATCH | 对资源进行部分修改 |
| update | PUT | 对资源进行完整更新(整个对象替换) |
| watch | GET | 监听资源的变化(流式更新) |
| proxy | GET | 通过 WebSocket 代理连接到资源 |
现实建议:
Kubernetes 为一些已知的系统身份(比如调度器)提供了大量内置的集群角色(ClusterRole),这些角色已经预先定义好了所需的权限。
# 查看内置角色
$ kubectl get clusterroles大多数内置角色是给系统组件用的,但其中四个是专门为普通用户准备的
大多数 Kubernetes 集群已经预先配置好了很多 ClusterRoleBinding(角色绑定)
$ kubectl get clusterrolebindings当 Kubernetes 的 API Server 启动时,会自动安装一批默认的ClusterRole,这些角色是直接写在 API Server 代码里的。
如果你手贱改了这些内置的 ClusterRole,这些修改是临时的。只要 API Server 一重启(比如升级、崩了重启、你自己手欠重启),你的修改会被直接覆盖掉,就像没发生过一样。
非要修改内置 ClusterRole,要给资源加一个 annotation,官方别动,我自己改了,你别给我恢复默认。
rbac.authorization.kubernetes.io/autoupdate: "false"
# 一旦设置为 false,API Server 就不会再自动覆盖这个 ClusterRole默认情况下,Kubernetes API Server 会创建一个ClusterRole,允许
system:unauthenticated 未认证用户 访问 API Server的 API
disconvery endpoint。没登录的人也能探测你 API 有啥接口
如果你的集群暴露在公网(或者任何不可信环境):一定要加这个参数
--anonymous-auth=false它就是个“权限自测工具”,用来回答一句话:“我能不能干这事?”
可以在配置集群时用 can-i 来验证权限设置是否正确
下面这个命令用于检查当前 kubectl 用户是否有权限创建 Pods:
$ kubectl auth can-i create pods还可以通过 --subresource
参数来测试子资源(比如日志或端口转发)
$ kubectl auth can-i get pods --subresource=logs像 Kubernetes 中的所有资源一样,RBAC 资源是用 YAML 来建模的。
kubectl 命令行工具提供了一个 reconcile
命令,它的行为有点类似
kubectl apply,用于将一组角色(Role)和角色绑定(RoleBinding)与当前集群的状态进行对齐(reconcile)。
kubectl auth reconcile -f some-rbac-config.yaml希望在实际应用更改之前先查看会发生哪些变化,可以给命令加上
--dry-run
参数,这样只会输出变更内容,而不会真正执行这些变更。
定义一种“组合角色”,把多个已有角色拼在一起用。
在 ClusterRole 里有个字段:
aggregationRule:
clusterRoleSelectors:定义一个label selector,意思是 这些匹配到的角色,其 rules 会被动态加入到当前 ClusterRole 的 rules 数组里。
靠谱的实践是,先定义很多细粒度(小而精)的ClusterRole,再用 aggregation 把它们组合成“大角色”。
Kubernetes 内置的 edit 角色就是这么干的:
aggregationRule:
clusterRoleSelectors:
- matchLabels:
rbac.authorization.k8s.io/aggregate-to-edit: "true"所有带有
rbac.authorization.k8s.io/aggregate-to-edit=true 这个标签的
ClusterRole:都会被自动合并到 edit 这个角色里。
在管理大量来自不同组织、但访问权限类似的用户时,通常最佳实践是使用“组(Group)”来管理角色绑定,而不是把绑定一个个加到具体用户身上。
为什么推荐用组?
如何把组绑定到 ClusterRole,在RoleBinding 和 ClusterRoleBinding里这样写
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: my-great-groups-namekind: Group 表示绑定的是组,name 组名。
最佳实践是尽早引入 RBAC,而不是事后补救。从一开始就打好正确的基础,远比后期再去修补要容易得多。
除了“容器”之外,“服务网格”已经成了云原生开发的代名词,概念很宽泛。
Kubernetes 一些网络基础组件,如 Service、Ingress,已经有网络能力了,为什么还要搞 Service Mesh。
原因是,Kubernetes 的网络模型 太基础了,理解方式基本是 你放访问哪个应用Pod我帮你转过去。
Service Mesh 干的事:
“别自己写加密,99%的人会写出灾难,交给 Service Mesh 自动搞。”
在微服务架构中,Pod 之间的网络流量加密是安全性的关键组成部分。由双向传输层安全(Mutual Transport Layer Security,简称 mTLS)提供的加密,是 Service Mesh 最常见的应用场景之一。
在 Kubernetes 集群中部署 Service Mesh,可以自动为集群中所有 Pod 之间的网络通信提供加密。Service Mesh 会为每个 Pod 注入一个 sidecar 容器,该容器会透明地拦截所有网络通信。
除了对通信进行加密之外,mTLS 还通过客户端证书为通信增加身份认证,使得应用程序可以安全地识别每一个网络客户端的身份。
实际运行时,每个微服务通常会有多个实例同时在跑。
当你把服务从版本 X 升级到版本 Y 时,在升级过程中,会有一段时间两个版本是同时运行的。
软件行业里有个经典玩法叫 dogfooding(自用测试):也就是在正式对外发布之前,先让公司内部的人用新版本。在这种模式下,你可能会让一部分用户(比如公司员工)使用版本 Y 持续几天甚至一周,而其他用户仍然使用版本 X。
为什么需要流量整形?根据请求的特征,把流量路由到不同的服务版本。
Service Mesh 的作用:把实验能力内置到基础设施里
你不需要:
你只需要声明规则,比如:
剩下的事情,Service Mesh 自动帮你搞定。
如果你像大多数程序员一样,一旦写完程序,就会不断地进行调试,因为新的错误会不断出现。查找代码中的错误,占据了大多数开发者的大量时间。
当应用被拆分成多个微服务时,调试会变得更加困难。当一个请求跨越多个 Pod 时,很难将其完整地串联起来。用于调试的信息必须从多个来源重新拼接,前提是这些相关信息一开始就被正确收集了。
自动化的自省能力是 Service Mesh 提供的另一个重要特性。由于它参与了 Pod 之间的所有通信,Service Mesh 知道请求被路由到了哪里,并且可以跟踪那些用于重建完整请求链路的信息。
开发者不再需要面对一堆来自不同微服务的零散请求,而是可以看到一个聚合后的完整请求,这个请求反映了用户在整个应用中的完整体验。
此外,Service Mesh 是在整个集群范围内统一实现的。这意味着无论服务是由哪个团队开发的,请求追踪机制都是一致的。所有监控数据在整个集群中也是统一和一致的。
Service Mesh 本质上是一个分布式系统,它会给你的应用设计增加额外的复杂度。而且,它是深度嵌入在微服务之间的通信路径中的。一旦 Service Mesh 出问题,你的整个应用都可能直接瘫痪。
在决定引入 Service Mesh 之前,你必须确认几件事:
对于很多小型应用来说,Service Mesh是过度设计。
你要是现在还在单体 + 两三个微服务,就别折腾了,先把业务跑起来再说。等哪天你开始怀疑人生(比如链路调试全靠猜),再回来考虑它。
Service Mesh 这套设计,本质就是:“我不信任你写网络代码,所以我把你所有流量劫持了。”
Service Mesh 会透明地拦截来自应用 Pod 的网络流量,并对其进行修改和在集群中重新路由,因此,Service Mesh 的一部分组件必须存在于每一个 Pod 中。
大多数 Service Mesh 实现都会在每个 Pod 中注入一个 sidecar(边车)容器。
由于这个 sidecar 与应用容器共享同一个网络栈,它可以利用诸如 iptables 或更新的 eBPF 等技术,对应用容器发出的网络流量进行监控(introspect)和拦截,并将其纳入 Service Mesh 的处理流程中。
大多数 Service Mesh 实现依赖一个 mutating admission controller(变更型准入控制器),在 Pod 创建时自动将 sidecar 注入进去。
Service Mesh 生态中最让人头疼的事情,大概就是选哪个 Mesh。
目前还没有哪个项目真正成为“行业标准”。虽然没有特别权威的统计数据,但最流行的很可能是 Istio。除了 Istio, https://github.com/istio/istio 还有不少开源方案,比如:
最适合你的 Service Mesh,很可能就是你云厂商已经帮你准备好的那个。
选错一次,未来几年都要为这个决定还债。
Service Mesh 确实很强:
代价也很真实
很多情况下,将状态从应用中解耦,并尽可能将微服务设计为无状态, 可以构建出最可靠、最易管理的系统。
Kubernetes 允许你把“外部世界”伪装成“集群内部服务” 听起来很优雅,本质上就是一层 DNS、转发表皮。
很多情况下,数据库并不在集群内运行,比如云数据库, 这种情况为了更好的维护,将外部服务进行建模为 Servuce ,依然可以利用 Kubernetes 内置的命名和服务发现机制。
测试环境
kind: Service
metadata:
name: my-database
# 注意这里是 'test' 命名空间
namespace: test
...生产环境
kind: Service
metadata:
name: my-database
# 注意这里是 'prod' 命名空间
namespace: prod
...test命名空间中,查询名 my-database 的服务
my-database.test.svc.cluster.internalprod命名空间中,查询 my-database 的服务
my-database.prod.svc.cluster.internal对于外部服务来说,Service 根据 selector 找Pod的机制直接失效了。
反而代之的,一般是一个DNS名称,指向运行数据库的真实服务器。
比如我们假设这个数据库服务器叫
database.company.com方式一:使用 ExternalName
dns-service.yaml
kind: Service
apiVersion: v1
metadata:
name: external-database
spec:
type: ExternalName
externalName: database.company.com工作原理是,正常情况,Kubernetes Service会分配一个Cluster IP, 在DNS里创建一个A记录(IP)。 ExternalName 不会分配IP,而是创建一个CNAME记录。
external-database.svc.default.cluster
↓
database.company.com
↓
真实数据库 IP方式二:只有IP没有DNS
如果没有域名,只有一个裸IP
创建没有 selector 的 Service
external-ip-service.yaml
kind: Service
apiVersion: v1
metadata:
name: external-ip-database这个Service会分配一个虚拟IP Cluster IP,创建A记录,因为没有 selector 所以不会自动生成 endpoints,负载均衡也不知道该转发到哪。
手动创建 Endpoints
external-ip-endpoints.yaml
kind: Endpoints
apiVersion: v1
metadata:
name: external-ip-database
subsets:
- addresses:
- ip: 192.168.0.1
ports:
- port: 3306告诉Kubernetes,别找Pod了,直接把流量打到这个IP上,如果有多个IP(做高可用)
addresses:
- ip: 192.168.0.1
- ip: 192.168.0.2限制:没有健康检查
外部Service,Kubernetes不会帮你做健康检查, 不会探活、不会自动摘除坏节点、不会帮你兜底。 Kubernetes:我帮你转发,剩下你自求多福。
在 Kubernetes 中运行存储系统的挑战在于:像 ReplicaSet 这样的原语假设每个容器都是完全相同且可以随意替换的。但现实是,大多数存储系统根本不是这么回事。
仍然使用 Kubernetes 的这些原语,但不去做存储的副本复制。换句话说,只运行一个 Pod,让它承载数据库或其他存储服务。
“你要是没到大厂规模,就别一上来搞分布式存储,把自己折腾到怀疑人生。”
如何在 Kubernetes 中以 Pod 的形式运行一个可靠的 MySQL 单实例数据库,以及如何将这个单实例暴露给集群中的其他应用。
创建PersistentVolume
nfs-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: database
labels:
volume: my-volume
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 1Gi
nfs:
server: 192.168.0.1
path: "/exports"该配置定义了一个容量为1GB的NFS持久卷,可以像往常一样创建
$ kubectl apply -f nfs-volume.yaml创建PersistentVolumeClaim
创建完持久卷后,需要通过 PersistentVolumeClaim(PVC)来声明使用它
nfs-volume-claim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: database
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
selector:
matchLabels:
volume: my-volumeselector 字段通过标签匹配之前定义的 PersistentVolume
使用ReplicaSet运行单实例Pod
为了在机器故障时自动恢复,我们使用 ReplicaSet(副本数为 1)来管理数据库。
mysql-replicaset.yaml
apiVersion: extensions/v1
kind: ReplicaSet
metadata:
name: mysql
# Labels so that we can bind a Service to this Pod
labels:
app: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: database
image: mysql
resources:
requests: cpu: 1
memory: 2Gi
env:
# Environment variables are not a best practice for security,
# but we're using them here for brevity in the example.
# See Chapter 11 for better options.
- name: MYSQL_ROOT_PASSWORD
value: some-password-here
livenessProbe:
tcpSocket:
port: 3306
ports:
- containerPort: 3306
volumeMounts:
- name: database
# /var/lib/mysql is where MySQL stores its databases
mountPath: "/var/lib/mysql"
volumes:
- name: database
persistentVolumeClaim:
claimName: database创建 ReplicaSet 后,它会自动创建一个运行 MySQL 的 Pod,并使用我们之前定义的持久卷。
暴露Service
把这个Pod暴露为Kubernetes Service
mysql-service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
protocol: TCP
selector:
app: mysql已经在集群中运行了一个可靠的 MySQL 单实例,并通过名为 mysql 的 Service 暴露出来,可以通过完整域名访问:
mysql.svc.default.cluster许多 Kubernetes 集群都支持动态卷供给。
使用这个功能时,集群管理员会创建一个或多个 StorageClass(存储类) 对象。
在 Kubernetes 中,StorageClass 用来描述一种存储的“类型和能力”,比如:
一个集群可以有多个 StorageClass,比如:
storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: default
annotations:
storageclass.beta.kubernetes.io/is-default-class: "true"
labels:
kubernetes.io/cluster-service: "true"
provisioner: kubernetes.io/azure-disk配置做了,创建一个名为 default 的存储类,设置为默认存储类,使用Azure作为底层存储。
以前需要:
现在可以:
dynamic-volume-claim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-claim
annotations:
volume.beta.kubernetes.io/storage-class: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi这段意思是,要一个10GB的存储,用default StorageClass,Kubernetes自己去创建磁盘并绑定。
| 问题 | 解决方式 |
|---|---|
| 手动创建 PV 太麻烦 | 自动创建 |
| 不同存储类型管理复杂 | StorageClass 抽象 |
| 云厂商差异 | provisioner 统一接口 |
Kubernetes 这套设计很优雅,但也很冷酷:它会自动帮你创建一切,也会自动帮你删除一切 包括你宝贵的数据。
持久卷的生命周期由 PersistentVolumeClaim 的回收策略决定,默认情况下,生命周期与创建卷的 Pod 的生命周期绑定。这意味着,如果您不小心删除了 Pod(例如,通过缩放或其他事件),那么卷也会被删除。虽然在某些情况下这可能是你想要的,但你必须小心谨慎,确保不会意外删除持久卷。
Kubernetes 1.5 版引入了 StatefulSets。
StatefulSets 是 Pod 的复制组,与 ReplicaSets 类似。但与 ReplicaSet 不同的是,它们具有某些独特的属性:
将使用 Stateful 对象创建一个由三个 MongoDB Pod组成的复制集。
mongo-simple.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongo
spec:
serviceName: "mongo"
replicas: 3
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
spec:
containers:
- name: mongodb
image: mongo:3.4.24
command:
- mongod
- --replSet
- rs0
ports:
- containerPort: 27017
name: peer与我们之前看到的 ReplicaSet 定义类似。唯一的变化是apiVersion和kind 字段。
$ kubectl apply -f mongo-simple.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mongo-0 1/1 Running 0 1m
mongo-1 0/1 ContainerCreating 0 10s在 Kubernetes 中,如果一个服务没有群集虚拟 IP 地址,它就被称为 “无头”服务。
创建 StatefulSet 后,需要创建 headless Service 管理 StatefulSet 的DNS条目。
在 StatefulSets 中,每个 Pod 都有一个唯一的身份,因此为复制的服务设置一个负载平衡 IP 地址并不合理。
mongo-service.yaml
apiVersion: v1
kind: Service
metadata:
name: mongo
spec:
ports:
- port: 27017
name: peer
clusterIP: None
selector:
app: mongo创建服务后,通常会填充四个DNS条目,
mongo.default.svc.cluster.local 所有主机名mongo-0.mongo.default.svc.cluster.local Pod
mongo-0mongo-1.mongo.default.svc.cluster.local Pod
mongo-1mongo-2.mongo.default.svc.cluster.local Pod
mongo-2使用这些每个 Pod 的主机名手动设置 Mongo 复制。我们将选择mongo-0.mongo 作为初始主节点。在该 Pod 中运行mongo 工具:
$ kubectl exec -it mongo-0 mongo
> rs.initiate( {
_id: "rs0",
members:[ { _id: 0, host: "mongo-0.mongo:27017" } ]
});
OK启动 Mongo ReplicaSet 后,可以在mongo-0.mongo Pod 上的mongo 工具中运行以下命令来添加其余副本:
> rs.add("mongo-1.mongo:27017");
> rs.add("mongo-2.mongo:27017");为了自动部署基于 StatefulSet 的 MongoDB 集群,我们将在 Pod 中添加一个容器来执行初始化。 为了配置这个 Pod 而无需构建新的 Docker 镜像,我们将使用 ConfigMap 在现有的 MongoDB 镜像中添加一个脚本。
Pod除了Mongo容器,在加一个init容器,用来执行我们事先设置好的脚本,脚本通过 configmap 映射
mongo-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mongo-init
data:
init.sh: |
#!/bin/bash
# Need to wait for the readiness health check to pass so that the
# Mongo names resolve. This is kind of wonky.
until ping -c 1 ${HOSTNAME}.mongo; do
echo "waiting for DNS (${HOSTNAME}.mongo)..."
sleep 2
done
until /usr/bin/mongo --eval 'printjson(db.serverStatus())'; do
echo "connecting to local mongo..."
sleep 2
done
echo "connected to local."
HOST=mongo-0.mongo:27017
until /usr/bin/mongo --host=${HOST} --eval 'printjson(db.serverStatus())'; do
echo "connecting to remote mongo..."
sleep 2
done
echo "connected to remote."
if [[ "${HOSTNAME}" != 'mongo-0' ]]; then
until /usr/bin/mongo --host=${HOST} --eval="printjson(rs.status())" \
| grep -v "no replset config has been received"; do
echo "waiting for replication set initialization"
sleep 2
done
echo "adding self to mongo-0"
/usr/bin/mongo --host=${HOST} \
--eval="printjson(rs.add('${HOSTNAME}.mongo'))"
fi
if [[ "${HOSTNAME}" == 'mongo-0' ]]; then
echo "initializing replica set"
/usr/bin/mongo --eval="printjson(rs.initiate(\
{'_id': 'rs0', 'members': [{'_id': 0, \
'host': 'mongo-0.mongo:27017'}]}))"
fi
echo "initialized"mongo.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongo
spec:
serviceName: "mongo"
replicas: 3
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
spec:
containers:
- name: mongodb
image: mongo:3.4.24
command:
- mongod
- --replSet
- rs0
ports:
- containerPort: 27017
name: mongo
volumeMounts:
- name: database
mountPath: /data/db
# 存活探针
livenessProbe:
exec:
command:
- /usr/bin/mongo
- --eval
- db.serverStatus()
initialDelaySeconds: 10
timeoutSeconds: 10
# 就绪探针
readinessProbe:
exec:
command:
- /usr/bin/mongo
- --eval
- db.serverStatus()
initialDelaySeconds: 5
timeoutSeconds: 5
- name: init-mongo
image: mongo:3.4.24
command:
- bash
- /config/init.sh
volumeMounts:
- name: config
mountPath: /config
volumes:
- name: config
configMap:
name: mongo-init
# 你必须提前准备 StorageClass(或者确保默认的存在),否则 PVC 会卡死。
volumeClaimTemplates:
- metadata:
name: database
spec:
accessModes:
- ReadWriteOnce
storageClassName: anything # 必须存在一个叫 anything 的 StorageClass kubectl get storageclass
resources:
requests:
storage: 100Gi当等一段时间,mongo就绪了 init.sh 后会进行些操作。
使用 StatefulSets、persistent volume claims、liveness probing,在Kubernetes上运行加固的、 可扩展的云原生MongoDB安装。
Kubernetes 本体只是个“内核”,真正的威力在“插件地狱”…哦不,是生态。
理解 Kubernetes API Server 是如何被扩展的,以及这些扩展是如何构建和交付的,都是解锁 Kubernetes 全部能力的关键。随着越来越多高级工具和平台基于这些扩展机制构建在 Kubernetes 之上,掌握它们的工作原理,对于在现代 Kubernetes 集群中构建应用至关重要。
一句话总结:
Kubernetes扩展 = 让K8s支持“你自己的业务对象” + 自动处理逻辑
扩展分两类
例如K8s默认认识,Pod、Deployment、Service,于是你说“K8s,你给我认识个新东西,叫 LoadTest”
这就是 CRD(CustomResourceDefinition)
apiVersion: stable.example.com/v1
kind: LoadTest
spec:
replicas: 10但,K8s,不知道要干嘛,需要加脑子 得有人干活,再写个程序 通常是Go,这个程序就是控制器
CRD(定义新资源)
+
Controller(写逻辑处理)| 组件 | 作用 |
|---|---|
| CRD | 定义“我要什么” |
| Controller | 负责“帮你实现” |
对 Kubernetes API Server 的扩展,要么是为集群增加新的功能,要么是对用户与集群交互的方式进行限制或调整。
扩展集群是一项高权限操作。这不是应该随便开放给任意用户或任意代码的能力,因为扩展集群需要具备集群管理员权限。
集群管理员,在安装第三方工具时也应当保持谨慎并进行充分审查。
普通人装浏览器插件顶多被偷点隐私,你这个要是乱装,可能直接把整个集群送走。挺刺激的。
扩展 Kubernetes 的方法很多,从 CustomResourceDefinitions 到 Container Network Interface 插件。
Kubernetes API 服务器的请求流

在讲API对象写入后备存储之前,会调用 接纳控制器,接纳控制器可以拒绝或修改 API 请求。 Kubernetes服务器内置了多个接纳控制器。
另一种扩展形式是自定义资源,它也可与接纳控制器结合使用。
创建新资源的第一步是通过自定义资源定义对其进行定义:
loadtest-resource.yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: loadtests.beta.kuar.com
spec:
group: beta.kuar.com
versions:
- name: v1
served: true
storage: true
scope: Namespaced
names:
plural: loadtests
singular: loadtest
kind: LoadTest
shortNames:
- lt对于自定义资源来说,名称比较特殊。它的格式必须是
<resource-plural>.<api-group>
格式,确保每个资源定义在群集中都是唯一的。
在spec 对象中,有一个 apigroup 字段提供了资源的 API 组。
$ kubectl get loadtests
# 会发现当前没有定义此类资源使用 loadtest-resource.yaml 创建资源:
$ kubectl create -f loadtest-resource.yaml
# 再次获取loadtests资源
$ kubectl get loadtests
# 会看到定义了一个 LoadTest 资源类型,但仍然没有该资源类型的实例与所有内置的 Kubernetes API 对象一样,可以使用 YAML 或 JSON 来定义自定义资源。
loadtest.yaml
apiVersion: beta.kuar.com/v1
kind: LoadTest
metadata:
name: my-loadtest
spec:
service: my-service
scheme: https
requestsPerSecond: 1000
paths:
- /index.html
- /login.html
- /shares/my-shares/可以使用 loadtest.yaml 文件创建资源,就像内置类型一样
$ kubectl create -f loadtest.yaml
$ kubectl get loadtests目前可以进行,创建、查询、删除,但啥也不会发生,只做了 定义了资源 没有 Controller。

Kubernetes OpenAPI 规范 https://github.com/kubernetes/kubernetes/tree/master/api/openapi-spec
最简单的控制器会运行一个 for 循环,不断轮询(poll)新的自定义对象,然后根据这些对象创建或删除对应的资源(例如 LoadTest 的 worker Pods)。更高效的方法是使用 API Server 的 watch API,它会在资源发生变化时提供事件流
验证入场控制器,我们需要将其指定为 Kubernetes ValidatingWebhookConfiguration, 该对象制指定了验证控制器运行的端点,以及验证控制器应运行的资源(LoadTest)和操作(CREATE)
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: kuar-validator
webhooks:
- name: validator.kuar.com
rules:
- apiGroups:
- "beta.kuar.com"
apiVersions:
- v1
operations:
- CREATE
resources:
- loadtests
clientConfig:
# Substitute the appropriate IP address for your webhook
url: https://192.168.1.233:8080
# This should be the base64-encoded CA certificate for your cluster,
# you can find it in your ${KUBECONFIG} file
caBundle: REPLACEMEKubernetes API 服务器访问的 webhook 只能通过 HTTPS 访问。 因此,我们需要生成证书,为网络钩子提供服务。最简单的方法是利用集群使用自己的证书颁发机构(CA)生成新证书的能力。
需要私钥和 证书签名请求 (CSR)。下面是一个生成这些文件的简单 Go 程序:
package main
import (
"crypto/rand"
"crypto/rsa"
"crypto/x509"
"crypto/x509/pkix"
"encoding/asn1"
"encoding/pem"
"net/url"
"os"
)
func main() {
host := os.Args[1]
name := "server"
key, err := rsa.GenerateKey(rand.Reader, 1024)
if err != nil {
panic(err)
}
keyDer := x509.MarshalPKCS1PrivateKey(key)
keyBlock := pem.Block{
Type: "RSA PRIVATE KEY",
Bytes: keyDer,
}
keyFile, err := os.Create(name + ".key")
if err != nil {
panic(err)
}
pem.Encode(keyFile, &keyBlock)
keyFile.Close()
commonName := "myuser"
emailAddress := "someone@myco.com"
org := "My Co, Inc."
orgUnit := "Widget Farmers"
city := "Seattle"
state := "WA"
country := "US"
subject := pkix.Name{
CommonName: commonName,
Country: []string{country},
Locality: []string{city},
Organization: []string{org},
OrganizationalUnit: []string{orgUnit},
Province: []string{state},
}
uri, err := url.ParseRequestURI(host)
if err != nil {
panic(err)
}
asn1, err := asn1.Marshal(subject.ToRDNSequence())
if err != nil {
panic(err)
}
csr := x509.CertificateRequest{
RawSubject: asn1,
EmailAddresses: []string{emailAddress},
SignatureAlgorithm: x509.SHA256WithRSA,
URIs: []*url.URL{uri},
}
bytes, err := x509.CreateCertificateRequest(rand.Reader, &csr, key)
if err != nil {
panic(err)
}
csrFile, err := os.Create(name + ".csr")
if err != nil {
panic(err)
}
pem.Encode(csrFile, &pem.Block{Type: "CERTIFICATE REQUEST", Bytes: bytes})
csrFile.Close()
}可以使用
$ go run csr-gen.go <URL-for-webhook>
# 生成两个文件 server.csr 和 server-key.pem可以使用以下 YAML 为 Kubernetes API 服务器创建证书签名请求:
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: validating-controller.default
spec:
groups:
- system:authenticated
request: REPLACEME
usages:
usages:
- digital signature
- key encipherment
- key agreement
- server authrequest 字段的值是REPLACEME ;这需要用我们在前面代码中生成的 base64 编码证书签名请求来替换:
$ perl -pi -e s/REPLACEME/$(base64 server.csr | tr -d '\n')/ \
admission-controller-csr.yaml证书签名已准备就绪,可以将其发送到API服务器以获取证书
$ kubectl create -f admission-controller-csr.yaml
# 接下来 需要批准该申请
$ kubectl certificate approve validating-controller.default
# 一旦获得批准,您就可以下载新证书
$ kubectl get csr validating-controller.default -o json | \
jq -r .status.certificate | base64 -d > server.crt有了证书,你终于可以创建一个基于 SSL 的准入控制器了
一般人用不到,自己定义资源类型。
公司内部搞PaaS:
kind: App
spec:
cpu: 2
memory: 4Gi开发只写这个,底层自动生成:
这时候 CRD 就是“抽象层”
天天再用,如 Prometheus Operator、Argo CD、Cert Manager 背后都是 CRD
kind: Prometheus
kind: Application
kind: Certificatekind: MongoCluster
kind: KafkaCluster控制器帮你处理:
kind: SuperApp,同事内心:“这什么鬼?Deployment
不香吗?”大部分内容都围绕使用声明式YAML配置展开(无论是直接通过kubectl,还是借助像Helm),但有些情况下, 需要从编程语言中直接与 Kubernetes API 进行交互。
Kubernetes 生态系统的大部分组件都是用 Go 语言编写的。因此,Go 语言拥有最丰富、最完善的客户端库。不过,大多数常见编程语言(甚至一些不那么常见的语言)也都有高质量的客户端实现。
Kubernetes的API Server本质就是一个HTTP(S)服务器。客户端在底层做了大量额外工作,用来实现各种 API 调用,以及在 JSON 之间进行序列化和反序列化。
你可以直接调 HTTP,但那是给自己找麻烦,客户端库已经帮你把坑都填了。
客户端代码不是人写的,是程序“生成”的。
可以把这个过程理解成一种“反向编译器”:
Kubernetes API 使用一种叫 OpenAPI 的格式来描述,这是目前最常见的 REST API 描述标准。
Kubernetes 还有一些不太 REST 的操作,比如:
这些客户端库也帮你封装好了。
kubectl 更像是一个“带脑子的脚本集合”,而不是 API 的简单壳。
kubectl 和 各种客户端主要通过两种方式获取认证信息:
kubeconfig文件在 ${HOME/.kube.config} 或环境变量
$KUBECONFIG 指定的位置(优先级更高)
文件内包含访问API Server所需的全部信息(证书、token、endpoint等)
config.load_kube_config()很多云厂商的认证方式是通过外部可执行程序生成token。这个程序通常是云厂商 CLI 工具的一部分。
如果代码运行在Kubernetes的Pod里,每个Pod都会自动关联一个 Service Account,
python
config.load_incluster_config()默认情况下,Pod绑定的Service Account权限非常有限,遇到一些权限不够 很正常。
你需要:
list_namespaced_xxxlist_xxx列出 default 命名空间中的Pod
api.list_namespaced_pods('default')列出所有Namespace
api.list_namespaces()API Group(API 分组)
在Kubernetes中,所有资源都被划分到不同API组中。如果你只用 kubectl,这个概念基本被“隐藏”了,最多就是在 YAML 里看到:
apiVersion: apps/v1每个API Group通常都有自己独立的客户端。例如
apps/v1 这个API GroupAppsV1Api()列出Pod
config.load_kube_config()
api = client.CoreV1Api()
pod_list = api.list_namespaced_pod('default')创建Pod
container = client.V1Container(
name="myapp",
image="my_cool_image:v1",
)
pod = client.V1Pod(
metadata = client.V1ObjectMeta(
name="myapp",
),
spec=client.V1PodSpec(containers=[container]),
)Kubernetes的客户端API,三种操作资源方式,create、replace、patch
Patch 听起来很优雅,但现实是:有点复杂(官方也承认了)很多时候还不如直接 replace 省事
把Deployment副本数改为3
deployment.spec.replicas = 3
api_response = api_instance.patch_namespaced_deployment(
name="my-deployment",
namespace="some-namespace",
body=deployment)最常见的任务之一就是:监听资源变化,然后根据变化执行对应操作
示例 监听Pod变化
config.load_kube_config()
api = client.CoreV1Api()
w = watch.Watch()
for event in w.stream(v1.list_namespaced_pods, "some-namespace"):
print(event)Kubernetes API 还提供了一些功能,用于直接与 Pod 中运行的应用程序交互。
kubectl 工具已经提供了几个常用命令,如 logs、exec、port-forward
logs,会建立一个长连接,Pod 每产生一行新日志,就会推送到这个连接里
config.load_kube_config()
api = client.CoreV1Api()
log = api_instance.read_namespaced_pod_log(
name="my-pod",
namespace="some-namespace"
)在Pod里执行命令并获取结果
cmd = ['ls', '/foo']
response = stream(
api_instance.connect_get_namespaced_pod_exec,
"my-pod",
"some-namespace",
command=cmd,
stderr=True,
stdin=False,
stdout=True,
tty=False
)可以把Pod的网络端口转发到本地程序,和 exec 一样:也是通过 WebSocket 实现的
pf = portforward(
api_instance.connect_get_namespaced_pod_portforward,
'my-pod',
'some-namespace',
ports='8080',
)Kubernetes API 提供了丰富而强大的功能,使你能够编写自定义代码。使用最适合特定任务或角色的编程语言来开发应用,可以让更多 Kubernetes 用户共享编排 API 的能力。
当你准备从简单地调用 kubectl 命令脚本,迈向更深入的开发时,Kubernetes 客户端库为你提供了一种直接操作 API 的方式,从而可以构建 Operator、监控代理、新的用户界面,或者任何你能想象得到的东西。
Kubernetes 提供了许多专注于安全的 API,使你能够构建一个安全的运行环境。
在 Kubernetes 中保护 Pod 时,理解以下两个概念非常重要:纵深防御(defense in depth) 和 最小权限原则(principle of least privilege)。
安全上下文(SecurityContext)是确保 Pod 安全的核心,以下是 SecurityContext 涵盖的一些安全控制示例:
kuard-pod-securitycontext.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
securityContext:
runAsNonRoot: true
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
privileged: false
ports:
- containerPort: 8080
name: http
protocol: TCP可以看到 Pod 和 容器 级别都有一个 SecurityContext,许多安全控制可以同时应用于这两个级别。 如果同时应用,则容器级配置优先。
privileged: true
,该选项将被设置为 true。$ kubectl create -f kuard-pod-securitycontext.yaml
pod/kuard created在容器内启动一个 shell,并检查进程是以哪个用户ID和组ID运行的
$ kubectl exec -it kuard -- ash
/ $ id
uid=1000 gid=3000 groups=2000
/ $ ps
PID USER TIME COMMAND
1 1000 0:00 /kuard
30 1000 0:00 ash
37 1000 0:00 ps
/ $ touch file
touch: file: Read-only file systemCapabilities 控“能干啥”,
允许为工作负载添加或移除某些权限集合,例如,你的应用可能需要修改宿主机的网络配置。与其将
Pod 设置为 privileged(基本等于拿到宿主机 root
权限),不如只添加特定的能力,比如用于网络管理的
NET_ADMIN。
这符合“最小权限原则”(Principle of Least Privilege)。
AppArmor 控“能碰哪些文件”,
AppArmor 用于控制进程可以访问哪些文件。
可以通过在 Pod 的 annotation 中添加如下配置,将 AppArmor 配置应用到容器:
container.apparmor.security.beta.kubernetes.io/<container_name>: <profile_ref><profile_ref 可选值包括
runtime/defaultlocalhost/<本地配置文件路径>unconfined默认值是 unconfined,也就是不启用任何限制
Seccomp 控“能调哪些系统调用”,
Seccomp(安全计算)配置文件用于创建系统调用(syscall)过滤器。
这些过滤器可以允许或阻止特定的系统调用,从而限制 Pod 中进程能够访问的 Linux 内核功能范围,减少攻击面。
SELinux 控“你是谁 + 你能干嘛”。
SELinux 用于定义文件和进程的访问控制。
ELinux 使用一组标签(labels)来构建安全上下文(注意,这个和 Kubernetes 的 SecurityContext 不是一回事)。
这些标签用于限制进程的访问权限。
默认情况下,Kubernetes 会为每个容器分配一个随机的 SELinux 上下文。不过,你也可以通过 SecurityContext 手动指定。
AppArmor 和 Seccomp 都支持设置“运行时默认配置”。
每个容器运行时(比如 containerd、Docker)都会自带一套默认的 AppArmor 和 Seccomp 配置,这些配置经过精心设计:
将使用一个叫做 amicontained(“我真的被隔离了吗”) 的工具
amicotained-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: amicontained
spec:
containers:
- image: r.j3ss.co/amicontained:v0.4.9
name: amicontained
command: [ "/bin/sh", "-c", "--" ]
args: [ "amicontained" ]创建 amicontainer Pod:
$ kubectl apply -f amicontained-pod.yaml
pod/amicontained created
# 查看日志,检查 amicontained 工具的输出
$ kubectl logs amicontained
Container Runtime: kube
Has Namespaces:
pid: true
user: false
AppArmor Profile: docker-default (enforce)
Capabilities:
BOUNDING -> chown dac_override fowner fsetid kill setgid setuid
setpcap net_bind_service net_raw sys_chroot mknod audit_write
setfcap
Seccomp: disabled
Blocked Syscalls (21):
SYSLOG SETPGID SETSID VHANGUP PIVOT_ROOT ACCT SETTIMEOFDAY UMOUNT2 SWAPON SWAPOFF REBOOT SETHOSTNAME SETDOMAINNAME INIT_MODULE
DELETE_MODULE LOOKUP_DCOOKIE KEXEC_LOAD FANOTIFY_INIT
OPEN_BY_HANDLE_AT FINIT_MODULE KEXEC_FILE_LOAD
Looking for Docker.sock从上面的输出可以看到,默认应用了 AppArmor 的运行时默认配置。还可以看到默认允许的 capabilities,同时 seccomp 是关闭的。最后可以看到默认阻止了 21 个系统调用(syscalls)。
amicontained-pod-securitycontext.yaml
apiVersion: v1
kind: Pod
metadata:
name: amicontained
annotations:
container.apparmor.security.beta.kubernetes.io/amicontained: "runtime/default"
spec:
securityContext:
runAsNonRoot: true
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
seccompProfile:
type: RuntimeDefault
containers:
- image: r.j3ss.co/amicontained:v0.4.9
name: amicontained
command: [ "/bin/sh", "-c", "--" ]
args: [ "amicontained" ]
securityContext:
capabilities:
add: ["SYS_TIME"] drop: ["NET_BIND_SERVICE"]
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
privileged: false删除老的Pod,用新的yaml创建
$ kubectl delete pod amicontained
pod "amicontained" deleted
$ kubectl apply -f amicontained-pod-securitycontext.yaml
pod/amicontained created
# 查看Pod日志,检查 amicontained 工具的输出
$ kubectl logs amicontained
Container Runtime: kube
Has Namespaces:
pid: true
user: false
AppArmor Profile: docker-default (enforce)
Capabilities:
BOUNDING -> chown dac_override fowner fsetid kill setgid setuid setpcap
net_raw sys_chroot sys_time mknod audit_write setfcap
Seccomp: filtering
Blocked Syscalls (67):
SYSLOG SETUID SETGID SETPGID SETSID SETREUID SETREGID SETGROUPS
SETRESUID SETRESGID USELIB USTAT SYSFS VHANGUP PIVOT_ROOT_SYSCTL ACCT
SETTIMEOFDAY MOUNT UMOUNT2 SWAPON SWAPOFF REBOOT SETHOSTNAME
SETDOMAINNAME IOPL IOPERM CREATE_MODULE INIT_MODULE DELETE_MODULE
GET_KERNEL_SYMS QUERY_MODULE QUOTACTL NFSSERVCTL GETPMSG PUTPMSG
AFS_SYSCALL TUXCALL SECURITY LOOKUP_DCOOKIE VSERVER MBIND SET_MEMPOLICY GET_MEMPOLICY KEXEC_LOAD ADD_KEY REQUEST_KEY KEYCTL MIGRATE_PAGES
FUTIMESAT UNSHARE MOVE_PAGES PERF_EVENT_OPEN FANOTIFY_INIT
NAME_TO_HANDLE_AT OPEN_BY_HANDLE_AT SETNS PROCESS_VM_READV
PROCESS_VM_WRITEV KCMP FINIT_MODULE KEXEC_FILE_LOAD BPF USERFAULTFD
PKEY_MPROTECT PKEY_ALLOC PKEY_FREE
Looking for Docker.sock怎么在大规模场景下,保证这些安全配置真的被统一执行?
Pod Security 允许您为 Pod 声明不同的安全配置文件。 这些安全配置文件被称为 Pod 安全标准,应用于命名空间级别。
有三种不同的标准,范围从限制到允许。
每种标准都使用给定的模式应用于命名空间,一项政策可应用于三种模式:
Pod 安全标准通过标签 应用于命名空间,具体如下:
pod-security.kubernetes.io/<MODE>: <LEVEL>pod-security.kubernetes.io/<MODE>-version: <VERSION>
(默认为最新版本)Pod Security 只需一个运行命令,就能轻松查看哪些现有工作负载违反了 Pod Security 标准:
$ kubectl label --dry-run=server --overwrite ns \
--all pod-security.kubernetes.io/enforce=baseline
Warning: kuard: privileged
namespace/default labeled
namespace/kube-node-lease labeled
namespace/kube-public labeled
Warning: kube-proxy-vxjwb: host namespaces, hostPath volumes, privileged
Warning: kube-proxy-zxqzz: host namespaces, hostPath volumes, privileged
Warning: kube-apiserver-kind-control-plane: host namespaces, hostPath volumes
Warning: etcd-kind-control-plane: host namespaces, hostPath volumes
Warning: kube-controller-manager-kind-control-plane: host namespaces, ...
Warning: kube-scheduler-kind-control-plane: host namespaces, hostPath volumes
namespace/kube-system labeled
namespace/local-path-storage labeled该命令根据 Pod 安全标准基线评估 Kubernetes 集群上的所有 Pod,并在输出中以警告信息的形式报告违规情况。
baseline-ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: baseline-ns
labels:
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: v1.22
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/audit-version: v1.22
pod-security.kubernetes.io/warn: restricted
pod-security.kubernetes.io/warn-version: v1.22$ kubectl apply -f baseline-ns.yaml
namespace/baseline-ns createdkuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
labels:
app: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP创建Pod并使用以下命令查看输出:
$ kubectl apply -f kuard-pod.yaml --namespace baseline-ns
Warning: would violate "v1.22" version of "restricted" PodSecurity profile:
allowPrivilegeEscalation != false (container "kuard" must set
securityContext.allowPrivilegeEscalation=false), unrestricted capabilities
(container "kuard" must set securityContext.capabilities.drop=["ALL"]),
runAsNonRoot != true (pod or container "kuard" must set securityContext.
runAsNonRoot=true), seccompProfile (pod or container "kuard" must set
securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
pod/kuard created可以看到Pod已经创建,但违反了受限制的Pod安全标准,输出中提供了违反标准的详细信息。
Service Account 是 Kubernetes 中的一种资源,用于为运行在 Pod 内的工作负载提供身份标识。可以通过 RBAC(基于角色的访问控制)将权限应用到 Service Account 上,从而控制该身份通过 Kubernetes API 可以访问哪些资源。更多内容请参见 基于角色的访问控制 章。
默认情况下,Kubernetes 会在每个命名空间中创建一个默认服务账户,并自动将其设置为所有 Pod 的服务账户。该服务账户包含一个令牌,会自动挂载在每个 Pod 中,用于访问 Kubernetes API。
要禁用此行为,必须在服务帐户配置中添加
automountServiceAccountToken: false
service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: default
automountServiceAccountToken: false“每个 Pod 都偷偷带着一个“API 通行证”(token)不用就别给权限,别等出事了才想起来 原来可以关掉”
前面 基于角色的访问控制 有单独的一个章节。
Kubernetes通过 容器运行时接口(CRI)与节点操作系统上的容器运行时进行交互。这个接口的创建和标准化,使得各种容器运行时生态得以存在。
容器运行时在隔离性方面各不相同,具体取决于它们的实现方式,因此可以提供不同级别的安全保障。例如:
RuntimeClass API 的引入,就是为了支持这种“运行时选择”能力。它允许用户从集群支持的一组容器运行时中选择一个来使用。
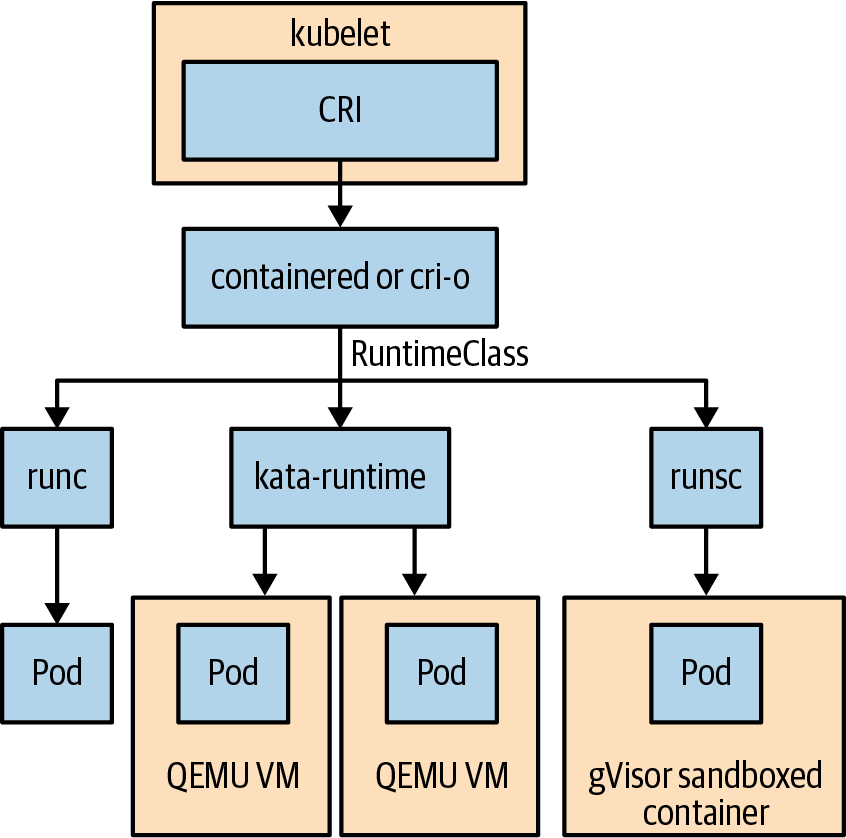
可以在Pod的配置中通过指定 runtimeClassName 来使用 RuntimeClass
kuard-pod-runtimeclass.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
labels:
app: kuard
spec:
runtimeClassName: firecracker
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCPKubernetes 还提供了一个 Network Policy API,用于为你的工作负载创建入口(ingress)和出口(egress)网络策略。
网络策略是通过 标签(labels) 来配置的,这样你就可以选择特定的 Pod,并定义它们如何与其他 Pod 或网络端点进行通信。
Network Policy 跟 Ingress 一样,并没有自带控制器(controller)。
NetworkPolicy 是命名空间级别(namespaced)资源,主要包含以下字段:
networkpolicy-default-deny.yaml 禁止所有进入流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress创建一个用于测试的命名空间
$ kubectl create ns kuard-networkpolicy
namespace/kuard-networkpolicy createdkuard-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
labels:
app: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP在命名空间 kuard-networkpolicy 中创建 kuard Pod
$ kubectl apply -f kuard-pod.yaml \
--namespace kuard-networkpolicy
pod/kuard created
# 将 kuard Pod 暴露为一个 Service:
$ kubectl expose pod kuard --port=80 --target-port=8080 \
--namespace kuard-networkpolicy
pod/kuard created随便启动一个Pod作为测试源,访问 kuard Pod
$ kubectl run test-source --rm -ti --image busybox /bin/sh \
--namespace kuard-networkpolicy
If you don't see a command prompt, try pressing enter.
/ # wget -q kuard -O -
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title><KUAR Demo></title>
...现在应用一个“默认拒绝”策略,后再次测试
networkpolicy-default-deny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress现在应用默认拒绝的网络策略:
$ kubectl apply -f networkpolicy-default-deny.yaml \
--namespace kuard-networkpolicy
networkpolicy.networking.k8s.io/default-deny-ingress created再从 test-source Pod 再次测试对 kuard Pod 访问,已经无法访问
$ kubectl run test-source --rm -ti --image busybox /bin/sh \
--namespace kuard-networkpolicy
If you don't see a command prompt, try pressing enter.
/ # wget -q --timeout=5 kuard -O -
wget: download timed out创建一个 Network Policy 允许 test-source 访问 kuard Pod
networkpolicy-kuard-allow-test-source.yaml
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: access-kuard
spec:
podSelector:
matchLabels:
app: kuard
ingress:
- from:
- podSelector:
matchLabels:
run: test-source应用 Network Policy
$ kubectl apply \
-f code/chapter-security/networkpolicy-kuard-allow-test-source.yaml \
--namespace kuard-networkpolicy
networkpolicy.networking.k8s.io/access-kuard created再次验证 test-source Pod 是否可以访问 kuard Pod
$ kubectl run test-source --rm -ti --image busybox /bin/sh \
--namespace kuard-networkpolicy
If you don't see a command prompt, try pressing enter.
/ # wget -q kuard -O -
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title><KUAR Demo></title>
...上面搞了,先全封,再按需开口子。
服务网格也可以用来提升你的工作负载的安全态势。
服务网格提供访问策略(access policies),允许基于服务配置具备协议感知能力的策略。例如,你的访问策略可能声明:ServiceA 通过 HTTPS 的 443 端口连接到 ServiceB。
此外,服务网格通常会在所有服务之间的通信中实现双向 TLS(mutual TLS)。这意味着通信不仅是加密的,同时服务的身份也会被验证。
有一些开源工具可以让你对 Kubernetes 集群运行一整套安全基准测试,用来判断你的配置是否符合一套预定义的安全基线。
kube-bench 可以用来运行 Kubernetes 的 CIS 基准(CIS Benchmarks)。
$ kubectl apply -f https://raw.githubusercontent.com/aquasecurity/kube-bench...
job.batch/kube-bench created通过查看 Pod 日志来审查基准测试的输出结果以及修复建议:
$ kubectl logs job/kube-bench
[INFO] 4 Worker Node Security Configuration
[INFO] 4.1 Worker Node Configuration Files
[PASS] 4.1.1 Ensure that the kubelet service file permissions are set to 644...
[PASS] 4.1.2 Ensure that the kubelet service file ownership is set to root ...
[PASS] 4.1.3 If proxy kubeconfig file exists ensure permissions are set to ...
...
...
If using command line arguments, edit the kubelet service file
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf on each worker node and
set the below parameter in KUBELET_SYSTEM_PODS_ARGS variable.
Based on your system, restart the kubelet service. For example:
systemctl daemon-reload
systemctl restart kubelet.service
...Pod 安全的另一个重要部分,是确保 Pod 内部的代码和应用本身是安全的。
对于容器镜像安全来说,基础包括:
Kubernetes集群中的资源数量会迅速增长,从一个微服务应用的几个资源,膨胀到一个完整分布式应用中的数百甚至数千个资源。
生产环境集群中,不难想象,管理成千上万个资源会带来多么巨大的挑战。
你要是不加“规矩”,Kubernetes很快就会从“自动化天堂”变成“分布式垃圾场”,而 policy + governance 给资源上狗链,防止团队成员各写各的奇怪YAML。
在Kubernetes有很多不同类型的策略,如
你可能希望在Kubernetes资源被创建之前就强制执行某些策略,这是“策略和治理”要解决的问题。
下面是一些集群管理员常见的策略示例:
集群管理员还可能希望:
图里展示了一个API请求通过 API Server的流程, 终点关注 变更型准入(mutating admission)和 验证型准入(validating admission)以及webhook。
本质:“所有资源进Kubernetes之前,都要过安检。”
流程大概是:
社区中存在一些开源解决方案。在这里,我们重点介绍一个开源生态项目:Gatekeeper https://github.com/open-policy-agent/gatekeeper
Gatekeeper 是一个 原生 Kubernetes 的策略控制器,它会根据定义好的策略对资源进行评估,并决定是否允许某个 Kubernetes 资源被创建或修改。这些评估是在 API 请求经过 Kubernetes API Server 时于服务端执行的,也就是说整个集群只有一个统一的处理入口。
Gatekeeper 就是 Kubernetes 的“保安 + 法官 + 改作业老师”, 你提交资源,它先检查,不合规直接拦下,还顺便告诉你错哪了。
Gatekeeper的组件会以Pod的形式运行在 gatekeeper-system 命名空间中,并配置一个 webhook 准入控制器。
使用 Helm 包管理器来安装 Gatekeeper
$ helm repo add gatekeeper https://open-policy-agent.github.io/gatekeeper/charts
$ helm install gatekeeper/gatekeeper --name-template=gatekeeper \
--namespace gatekeeper-system --create-Gatekeeper的安装需要 cluster-admin 权限,不同版本可能行为不一样,所以别偷懒,去看官方文档确认你用的是哪个版本。
验证安装,安装完成后,确认 Gatekeeper是否正常运行
$ kubectl get pods -n gatekeeper-system
NAME READY STATUS RESTARTS AGE
gatekeeper-audit-54c9759898-ljwp8 1/1 Running 0 1m
gatekeeper-controller-manager-6bcc7f8fb5-4nbkt 1/1 Running 0 1m
gatekeeper-controller-manager-6bcc7f8fb5-d85rn 1/1 Running 0 1m
gatekeeper-controller-manager-6bcc7f8fb5-f8m8j 1/1 Running 0 1m看到这些Pod都是Running,说明至少没把集群搞炸。
查看 Webhook 配置
$ kubectl get validatingwebhookconfiguration -o yaml
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
labels:
gatekeeper.sh/system: "yes"
name: gatekeeper-validating-webhook-configuration
webhooks:
- admissionReviewVersions:
- v1
- v1beta1
clientConfig:
service:
name: gatekeeper-webhook-service
namespace: gatekeeper-system
path: /v1/admit
failurePolicy: Ignore
matchPolicy: Exact
name: validation.gatekeeper.sh
namespaceSelector:
matchExpressions:
- key: admission.gatekeeper.sh/ignore
operator: DoesNotExist
rules:
- apiGroups:
- '*'
apiVersions:
- '*'
operations:
- CREATE
- UPDATE
resources:
- '*'
sideEffects: None
timeoutSeconds: 3
...上面输出里的rules部分:
* 的 CREATE 和 UPDATE
操作都会被发送到webhook准入控制器admission.gatekeeper.sh/ignore
标签的命名空间,才会被纳入策略评估范围创建 ConstraintTemplate allowedrepos-constraint-template.yaml
K8sAllowedRepos 是 Gatekeeper 使用的自定义资源的一部分。
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8sallowedrepos
annotations:
description: Requires container images to begin with a repo string from a
specified list.
spec:
crd:
spec:
names:
kind: K8sAllowedRepos
validation:
# Schema for the `parameters` field
openAPIV3Schema:
properties:
repos:
type: array
items:
type: string
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8sallowedrepos
violation[{"msg": msg}] {
container := input.review.object.spec.containers[_]
satisfied := [good | repo = input.parameters.repos[_] ; good = starts...
not any(satisfied)
msg := sprintf("container <%v> has an invalid image repo <%v>, allowed...
}
violation[{"msg": msg}] {
container := input.review.object.spec.initContainers[_]
satisfied := [good | repo = input.parameters.repos[_] ; good = starts...
not any(satisfied)
msg := sprintf("container <%v> has an invalid image repo <%v>, allowed...)
}使用命令创建约束模板
$ kubectl apply -f allowedrepos-constraint-template.yaml
constrainttemplate.templates.gatekeeper.sh/k8sallowedrepos created约束允许default 命名空间中所有前缀为 gcr.io/kuar-demo/
的容器。enforcementAction 设置为
“deny”:任何不符合要求的资源都将被拒绝。
allowedrepos-constraint.yaml
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sAllowedRepos
metadata:
name: repo-is-kuar-demo
spec:
enforcementAction: deny
match:
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces:
- "default"
parameters:
repos:
- "gcr.io/kuar-demo/"$ kubectl create -f allowedrepos-constraint.yaml
k8sallowedrepos.constraints.gatekeeper.sh/repo-is-kuar-demo created下面创建一些Pod来测试策略是否生效。
合规的 compliant-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:blue
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP$ kubectl apply -f compliant-pod.yaml
pod/kuard created不合规的 noncompliant-pod.yaml 镜像来源不符合规矩
apiVersion: v1
kind: Pod
metadata:
name: nginx-noncompliant
spec:
containers:
- name: nginx
image: nginx$ kubectl apply -f noncompliant-pod.yaml
Error from server ([repo-is-kuar-demo] container <nginx> has an invalid image
repo <nginx>, allowed repos are ["gcr.io/kuar-demo/"]): error when creating
"noncompliant-pod.yaml": admission webhook "validation.gatekeeper.sh" denied
the request: [repo-is-kuar-demo] container <nginx> has an invalid image
repo <nginx>, allowed repos are ["gcr.io/kuar-demo/"]策略经常会随着时间的推移而改变,你也可以使用 Gatekeeper 来确认当前部署的所有资源是否仍然合规。
Gatekeeper 在评估资源(比如 Pod)时,会根据你写的约束(Constraint)判断“合不合规”
enforcementAction 决定 发现违规之后怎么处理。
allowdrepos-constraint-dryrun.yaml
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sAllowedRepos
metadata:
name: repo-is-kuar-demo
spec:
enforcementAction: dryrun
match:
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces:
- "default"
parameters:
repos:
- "gcr.io/kuar-demo/"运行命令更新约束
$ kubectl apply -f allowedrepos-constraint-dryrun.yaml
k8sallowedrepos.constraints.gatekeeper.sh/repo-is-kuar-demo configured使用命令创建不符合要求的Pod
$ kubectl apply -f noncompliant-pod.yaml
pod/nginx-noncompliant created
$ kubectl get constraint repo-is-kuar-demo -o yaml
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sAllowedRepos
...
spec:
enforcementAction: dryrun
match:
kinds:
- apiGroups:
- ""
kinds:
- Pod
namespaces:
- default
parameters:
repos:
- gcr.io/kuar-demo/
status:
auditTimestamp: "2021-07-14T20:05:38Z"
...
totalViolations: 1
violations:
- enforcementAction: dryrun
kind: Pod
message: container <nginx> has an invalid image repo <nginx>, allowed repos
are ["gcr.io/kuar-demo/"]
name: nginx-noncompliant
namespace: default在 status 部分,可以看到 auditTimestamp,这是最后一次运行审核。totalViolations 列出违反此限制的资源数量,violations 列出了违规情况,nginx-noncompliant Pod 处于违规状态。
已经介绍了如何使用约束条件来验证资源是否合规。那么如何修改资源使其符合要求呢?这可以通过 Gatekeeper 的 Mutation 功能来处理。
前面,我们讨论了两种不同类型的接纳 webhook:mutating 和 validating。 默认情况下,Gatekeeper 只作为验证型接纳 webhook 部署,但也可以配置为 mutating 型接纳 webhook。
imagepullpolicyalways-mutation.yaml
apiVersion: mutations.gatekeeper.sh/v1alpha1
kind: Assign
metadata:
name: demo-image-pull-policy
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
match:
scope: Namespaced
kinds:
- apiGroups: ["*"]
kinds: ["Pod"]
excludedNamespaces: ["system"]
location: "spec.containers[name:*].imagePullPolicy"
parameters:
assign:
value: Always创建 mutation 任务
$ kubectl apply -f imagepullpolicyalways-mutation.yaml
assign.mutations.gatekeeper.sh/demo-image-pull-policy created创建一个Pod,没有显示设置 imagePullPolicy 默认情况下为 IfNotPresent,我们希望 Gatekeeper 将该字段变为 Always
$ kubectl apply -f compliant-pod.yaml
pod/kuard created运行以下程序,验证 imagePullPolicy 是否已成功变为 Always
$ kubectl get pods kuard -o=jsonpath="{.spec.containers[0].imagePullPolicy}"
Always$ kubectl delete -f compliant-pod.yaml
pod/kuard deleted
$ kubectl delete -f imagepullpolicyalways-mutation.yaml
assign.mutations.gatekeeper.sh/demo-image-pull-policy deleted与 validation 不同,mutation 提供了一种代表集群管理员自动修复不合规资源的方法。
在编写约束时,可能需要将一个字段的值与另一个资源中的字段值进行比较。确保集群的入口主机名是唯一的就是一个需要这样做的具体例子。
默认情况下,Gatekeeper 只能评估当前资源中的字段:如果需要跨资源比较以执行策略,则必须进行配置。可以将 Gatekeeper 配置为将特定资源缓存到 Open Policy Agent 中,以便进行跨资源比较。
下面 config-sync.yaml 将Gatekeeper配置为缓存 Namespace 和 Pod 资源。
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: ""
version: "v1"
kind: "Namespace"
- group: ""
version: "v1"
kind: "Pod"uniqueingressshot-constraint-template.yaml
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8suniqueingresshost
annotations:
description: Requires all Ingress hosts to be unique.
spec:
crd:
spec:
names:
kind: K8sUniqueIngressHost
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8suniqueingresshost
identical(obj, review) {
obj.metadata.namespace == review.object.metadata.namespace
obj.metadata.name == review.object.metadata.name
}
violation[{"msg": msg}] {
input.review.kind.kind == "Ingress"
re_match("^(extensions|networking.k8s.io)$", input.review.kind.group)
host := input.review.object.spec.rules[_].host
other := data.inventory.namespace[ns][otherapiversion]["Ingress"][name]
re_match("^(extensions|networking.k8s.io)/.+$", otherapiversion)
other.spec.rules[_].host == host
not identical(other, input.review)
msg := sprintf("ingress host conflicts with an existing ingress <%v>"...
}数据复制是一个功能强大的工具,可以跨Kubernetes资源进行比较,建议只在有Policy要求它发挥作用时才配置它,如果使用它 请将其范围限定在相关资源上。
Gatekeeper以Prometheus格式发布指标,以实现持续的资源合规性监控。
如设置给 Gatekeeper 的约束、约束模板和请求的数量,可以查看有关 Gatekeeper 整体健康情况的简单指标。
Gatekeeper项目的核心宗旨之一是创建可在企业间共享的可重用Policy库。
共享策略可以减少模板式的策略工作,让集群管理员专注于应用策略而不是编写策略。
https://github.com/open-policy-agent/gatekeeper-library
介绍了基于 Open Policy Agent 构建的 Kubernetes 本机策略控制器 Gatekeeper 项目,并向您展示了如何使用它来满足您的策略和治理要求。从编写策略到审核。
现实世界的需求意味着多集群应用程序部署是大多数应用程序的现实。
第一个要求是冗余和弹性,无论是云中还是企业内部,单个数据中心通常都是 单一障域。无论是光缆断了、冰雪暴风停电,还是软件更新失败,任何部署在单一 地点的应用都可能完全失效,让用户束手无策。
许多情况下,单个Kubernetes集群与单个位置绑定,因此是单个故障域。
除弹性要求外,多集群部署的另一个强大驱动力是某些业务或应用对区域亲和性的需求。 例如,游戏服务器强烈要求靠近玩家,以减少网络延迟并改善游戏体验。其他应用可能受法律或监管要求的制约,需要将数据放置在特定的地理区域内。由于任何 Kubernetes 集群都与特定地点绑定,这些将应用部署到特定地域的需求意味着应用必须跨越多个集群。
保持稳定基础的最重要部分之一就是保持所有群集的一致性。这有利于自动化管理,不然比如 kubernetes 版本不一致,那是非常糟糕的。
虽然 Kubernetes 支持基于证书的简单身份验证,但我们强烈建议使用与全局身份提供商的集成,如 Azure Active Directory 或任何其他兼容 OpenID Connect 的身份提供商。
一旦开始考虑将应用程序部署到多个地点,就必须考虑用户如何访问应用程序。通常情况下,这是通过域名(如 my.company.com)来实现的。
DNS 查询是负载平衡策略的首选。在许多传统的负载平衡方法中,DNS 查询用于将流量路由到特定位置。这通常被称为 “GeoDNS”。在 GeoDNS 中,DNS 查询返回的 IP 地址与客户端的物理位置相关联。该 IP 地址通常是离客户端最近的区域集群。
使用 DNS 选择群集的另一个替代方法是负载平衡技术,即任意广播。任播网络中,IP 地址实际上是一个虚拟 IP 地址,它会根据你的网络位置路由到不同的位置。 根据网络性能而不是地理距离,流量会被路由到 “最近”的位置。任播网络通常能产生更好的效果,但并非所有环境都能使用。
设计负载平衡时的最后一个考虑因素是,负载平衡是在 TCP 层还是 HTTP 层进行。
理想情况下,您的应用程序不需要状态,或者所有状态都是只读的。在这种情况下,您几乎不需要做什么来支持多集群部署。 您可以将应用程序单独部署到每个集群中,然后在顶部添加一个负载平衡器,这样您的多集群部署就完成了。
不幸的是,对于大多数应用程序来说,必须以一致的方式管理应用程序副本中的状态。如果不能正确处理状态,用户最终将获得混乱、有缺陷的体验。
为了了解复制状态如何影响用户体验,我们以一个简单的零售店为例。很明显,如果只在多个集群中的一个集群中存储客户的订单,那么当客户的请求移动到不同地区时,客户可能会因为负载均衡或实际地理位置的移动而无法看到自己的订单,这种体验令人不安。因此,用户的状态显然需要跨区域复制。但复制方法也会影响客户体验,这一点可能不太清楚。这个问题简明扼要地概括了复制数据和客户体验所面临的挑战:“我能读自己写的吗?答案应该是”可以”,这似乎显而易见,但要做到这一点却比想象的要难。举例来说,一位客户在电脑上下单后,立即尝试在手机上查看订单。他们可能会从两个完全不同的 Network+ 访问您的应用程序,从而登陆两个完全不同的集群。 用户对能否看到自己刚下的订单的期望就是数据一致性的一个例子。
在为多种环境设计应用程序之前,选择一致性模型是重要的第一步。
把你的应用复制到多个集群、多个区域,最简单粗暴的方法就是——到处拷贝一份。没错,就是这种听起来像“Ctrl+C / Ctrl+V工程学”的方案。
每个区域里的应用实例都是完全一样的克隆体,不管跑在哪个集群,看起来都一模一样。因为最上层有负载均衡器帮你分发用户请求,同时你也在需要保存状态的地方做好了数据复制,所以应用本身其实不需要做太多改动就能支持这种模式。
当然,具体要看你选的数据一致性模型。如果数据在不同区域之间复制不够快,你就得接受“数据可能没那么及时同步”的现实。不过如果你选择强一致性,这通常也不需要对应用进行大规模重构。
当你这样设计应用时,每个区域就像一个独立的小岛(silo)。
这个区域所需要的所有数据都在本地,一旦请求进入这个区域,整个处理过程都会在该区域的那个集群内完成。
这种方式的好处很明显:简单,清晰,脑子不用太累。
但代价嘛,也很经典:效率低得让人心疼钱。
随着你的应用不断扩展,你很可能会在“区域孤岛(regional silo)”这种架构下遇到一个经典烦恼:把所有数据在全球范围内复制,越来越贵,而且越来越浪费。
把数据复制一份用来提高可靠性,这事本身没毛病。但问题是,你的应用数据并不需要在每一个部署的集群里都放一份。现实一点,大多数用户只会在少数几个地理区域访问你的应用,而不是满世界乱窜。
更麻烦的是,当你的应用开始“全球开花”之后,还会撞上各种监管和法律要求,比如数据本地化(data locality)。有些国家会明确规定:用户的数据必须存储在本国境内。换句话说,不是你想放哪就能放哪。
这些现实压力叠加在一起,最终逼你走向一个结论:你必须开始考虑按区域进行数据分片(regional data sharding)。
所谓分片,就是把数据拆开,不再让每个集群都拥有全部数据。显然,这会直接影响你的应用设计,毕竟你再也不能假装“数据无处不在”了。
假设你的应用部署在 6 个区域集群中:A、B、C、D、E、F。
你把数据拆成 3 个分片(shard):1、2、3。
部署方式可能这样
| 集群 | 数据分片 |
|---|---|
| A | 1 |
| B | 2 |
| C | 3 |
| D | 1 |
| E | 2 |
| F | 3 |
1/3 的数据现在每个集群只知道自己那一份数据,于是你必须解决一个新问题:请求到底该发到哪个分片?
这就需要一个额外的路由层(routing layer),负责判断:
别做蠢事:不要把路由写进客户端,把数据路由做成一个独立的微服务(microservice)
之前讨论多集群应用开发中的“区域孤岛(regional silo)”方案时提到,它可能会降低成本效率。但问题不止于钱,它对灵活性的伤害也不小。
构建这种“孤岛”结构时,本质上是在更大尺度上重新造了一遍“单体应用(monolith)”。而容器和 Kubernetes 本来就是为了把这种大块头拆开的。结果你又亲手把它拼回去了,挺有意思的。
更糟的是,这种设计会强迫应用里的所有微服务同时扩展到相同数量的区域。 如果你的应用很小,这种“一刀切”还说得过去。但一旦服务规模变大,尤其是开始被多个应用复用时,这种“类单体”的多集群架构会严重限制灵活性。
再加一层现实暴击: 如果“集群”是部署单位,而 CI/CD 又绑定在集群上,那所有团队都必须使用同一套发布流程和节奏。适不适合?不重要,反正大家一起受罪。
举个例子,假设你有一个巨型应用,部署在 30 个集群上,同时还有一个正在开发的小应用。让一个刚起步的小团队,一上来就按 30 个集群的规模部署?听起来就像让实习生第一天就接手整个支付系统,挺刺激的,但不太聪明。
更好的方式是:
把应用里的每一个微服务都当成“对外服务”来设计。别误会,它不一定真的要对公网开放,但在架构上应该具备这些特征:
这样一来:
把应用部署到多个集群确实会让事情变复杂,这点谁也骗不了你。但现实世界的需求和用户的期望基本就是在逼你这么干,大多数稍微像样一点的应用都逃不掉。
如果你一开始就按“多集群”来设计应用和基础设施,而不是等系统烂成一锅粥再补救,那你会得到两个好处:
在多集群部署里,最关键的一环就是:如何管理应用的配置和部署流程。这玩意要是搞不好,你的系统再高级也只是“分布在多个地方的混乱”。
不管你的应用是按区域部署,还是跨多个集群,接下来的章节都会帮你做到一件事:又快又稳地把应用部署出去,而不是每次上线都像拆炸弹一样紧张。
经过学习已经了解 如何将程序封装为容器,将这些容器放入Pods中,使用 ReplicaSets 来复制这些Pods,并通过 Deployments 进行发布和滚动更新。
在实际工作中,应该如何真正地管理和操作这样一个应用?
在 Kubernetes 上开发云原生应用的总体目标是可靠性和敏捷性,但这些目标究竟如何与应用的维护和部署设计相关联呢?
开始解除 Kubernetes,通常会使用命令式交互,你会运行 kubectl run、kubectl edit 之类的命令,在集群中创建或修改 Pod 或其他对象。
即使后来开始使用 YAML 文件,这些文件也往往被当作一种临时工具,好像它只是通往修改集群状态路上的一个中转站。但在真正的生产级应用中,情况应该完全相反。一定要使用YAML。
与其把集群的状态(etcd 中的数据)当作事实来源,不如把存放 YAML 对象的文件系统当作应用的事实来源。
“所有部署到Kubernetes的应用,必须先用文件描述,并存储在文件系统中。”
把集群状态放进文件系统(Git)有一些现实的好处:
多人协作变得简单,支持多人编辑,版本可追踪,冲突可见,回滚简单,审核清晰。
不久之前,对应用程序源代码进行代码评审还是一种新鲜事物。但现在已经很明确,在代码提交到应用程序之前由多个人进行审查,是生成高质量、可靠代码的最佳实践。
根据我们的经验,大多数服务宕机其实都是“自己作的”——比如意料之外的配置后果、拼写错误,或者其他看起来不起眼但足以把系统送进急诊室的小错误。确保任何配置变更至少由两个人审查,可以显著降低这类错误发生的概率。
应用程序源代码和配置是否应该放在同一个仓库中?
对于小型项目来说,这样做是可行的,但在大型项目中,通常更合理的做法是将两者分开。即使是同一批人既负责构建应用又负责部署应用,构建者(builder)和部署者(deployer)的视角差异仍然足够大,因此进行关注点分离是有意义的。
如果代码仓库和配置仓库是分开的,如何把源代码中新功能的开发与生产环境中的功能部署连接起来?
当开发一个新功能时,整个开发过程都放在一个功能标志(feature flag)或功能门(feature gate)之后进行。
if (featureFlags.myFlag) {
// 新功能实现
}功能代码可以先进入主分支,但默认不生效,除非打开开关。
这样的好处是:
featureFlags:
myFlag: true应该如何在文件系统中组织这些文件。
文件系统是由分层的目录结构组成的,而源代码控制系统(source-control system)又在此基础上增加了诸如 标签(tags)和分支(branches) 等概念。
别再靠 kubectl edit 这种手工魔法了,而是老老实实用 Git + 目录结构 + 分支策略 来管理。
应用组织的第一个维度应该是语义组件或层级(例如 frontend 或 batch work queue)。
对于一个拥有 frontend,并使用两个 service 的应用,文件系统可能是这样:
frontend/
service-1/
service-2/在这些目录中,存放的是每个应用的配置文件。这些文件就是 YAML 配置文件,它们直接表示集群的当前状态。
在同一个文件名中同时包含服务名称和 Kubernetes 对象类型
虽然Kubernetes允许在YAML文件中放多个对象,但这通常是一种反模式(antipattern)。
把 Deployment、Service、ConfigMap、Ingress 全塞进一个 YAML 文件,就像把数据库、HTTP服务器、日志系统和支付接口写进一个 C++ 类里一样。能编译,但会被人记仇。
frontend/
frontend-deployment.yaml
frontend-service.yaml
frontend-ingress.yaml
service-1/
service-1-deployment.yaml
service-1-service.yaml
service-1-configmap.yaml
...让文件系统结构本身就表达系统结构
第一种方式:使用标签(tags)、分支(branches)以及版本控制系统本身的功能。
第二种方式:在文件系统中克隆配置,并使用不同目录表示不同版本。
这两种方式在管理发布版本的能力上是等价的,最终只是审美和团队习惯的选择。
| 方式 | 核心思想 | 适合团队 |
|---|---|---|
| Git tags/branches | 配置就是代码版本 | 熟悉 Git 工作流的团队 |
| 目录版本化 | 每个版本一个目录 | 运维/平台团队 |
更新发布版本的配置会稍微复杂一点,不过整体思路和源码控制中的常规操作是一样的:
git cherry-pick <edit>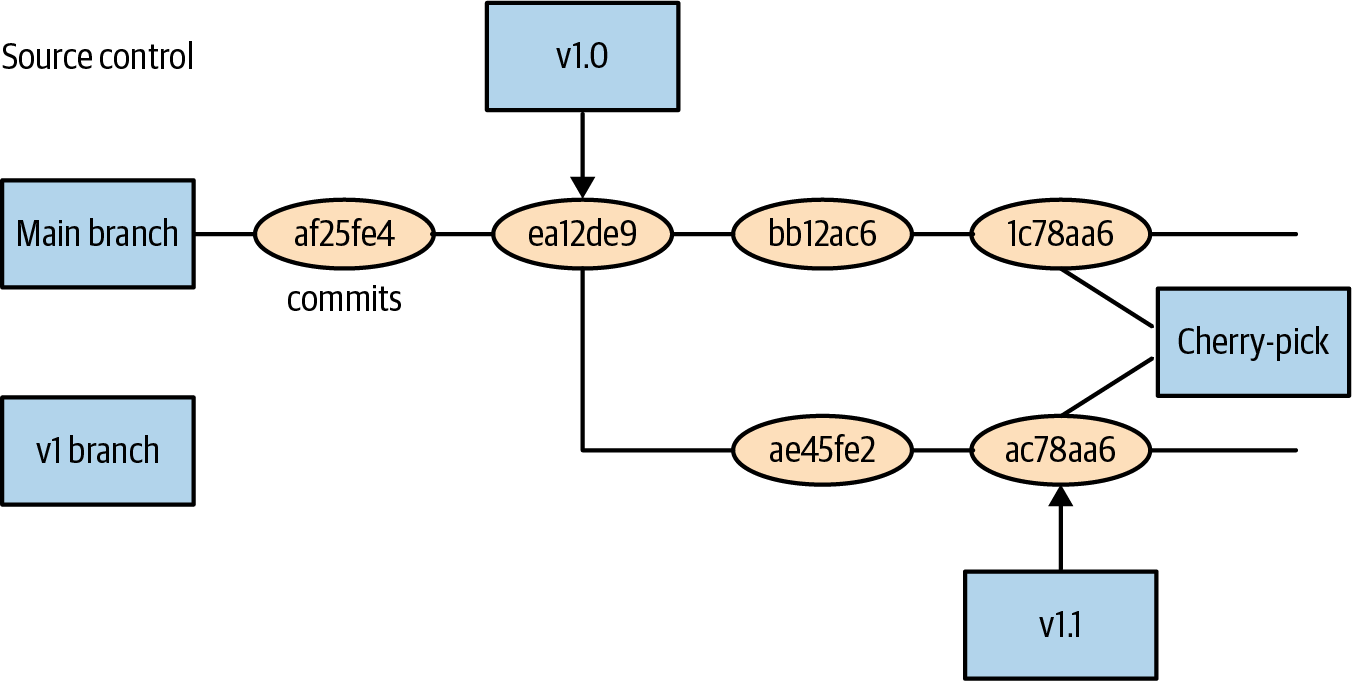
HEAD 永远向前开发,发布版本用tag固定,修复用 branch + cherry-pick
frontend/
v1/
frontend-deployment.yaml
frontend-service.yaml
current/
frontend-deployment.yaml
frontend-service.yaml
service-1/
v1/
service-1-deployment.yaml
service-1-service.yaml
v2/
service-1-deployment.yaml
service-1-service.yaml
current/
service-1-deployment.yaml
service-1-service.yaml
...创建新版本的方式,当需要创建一个新的发布版本时:直接把 current 目录复制一份,生成一个新的版本目录。
cp -r current v3修复旧版本 Bug 时的做法,当你需要对某个发布版本进行 Bug 修复 时:你的 Pull Request 必须同时修改所有相关版本目录中的 YAML 文件
service-1/v1/service-1-deployment.yaml
service-1/v2/service-1-deployment.yaml
service-1/current/service-1-deployment.yaml相比前面提到的 cherry-pick 版本修复方式,这种方式有一个明显优势:在一个变更请求中,可以清晰地看到所有版本都被同步修改了
除了按照周期性发布节奏来组织应用之外,你还需要以支持敏捷开发(Agile development)、高质量测试(quality testing)以及安全部署(safe deployment) 为目标来组织你的应用结构。
这样做可以让开发人员能够快速地对分布式应用进行修改和测试,并且将这些变更安全地发布给客户。
第一个目标是让每个开发者都能够轻松地为应用开发新功能。 现实世界通常是这样的:一个开发者只改一个组件,但这个组件偏偏和集群里的所有微服务都有关系。于是事情就变得很有趣了(有趣的意思是:谁改谁崩,谁崩谁背锅)。
为了促进开发,开发者必须能够在自己的独立环境中工作,并且所有服务都可以使用。
第二个目标是让应用在部署之前能够进行简单且准确的测试结构设计。你必须在上线前就把问题测出来,而不是上线后让用户帮你测。
开发 → 测试 → 上线 → 用户发现 bug → 深夜回滚 → 人类开始怀疑人生
在源代码控制系统中添加一个 development 标签,使用自动化流程不断将这个标签向前推进
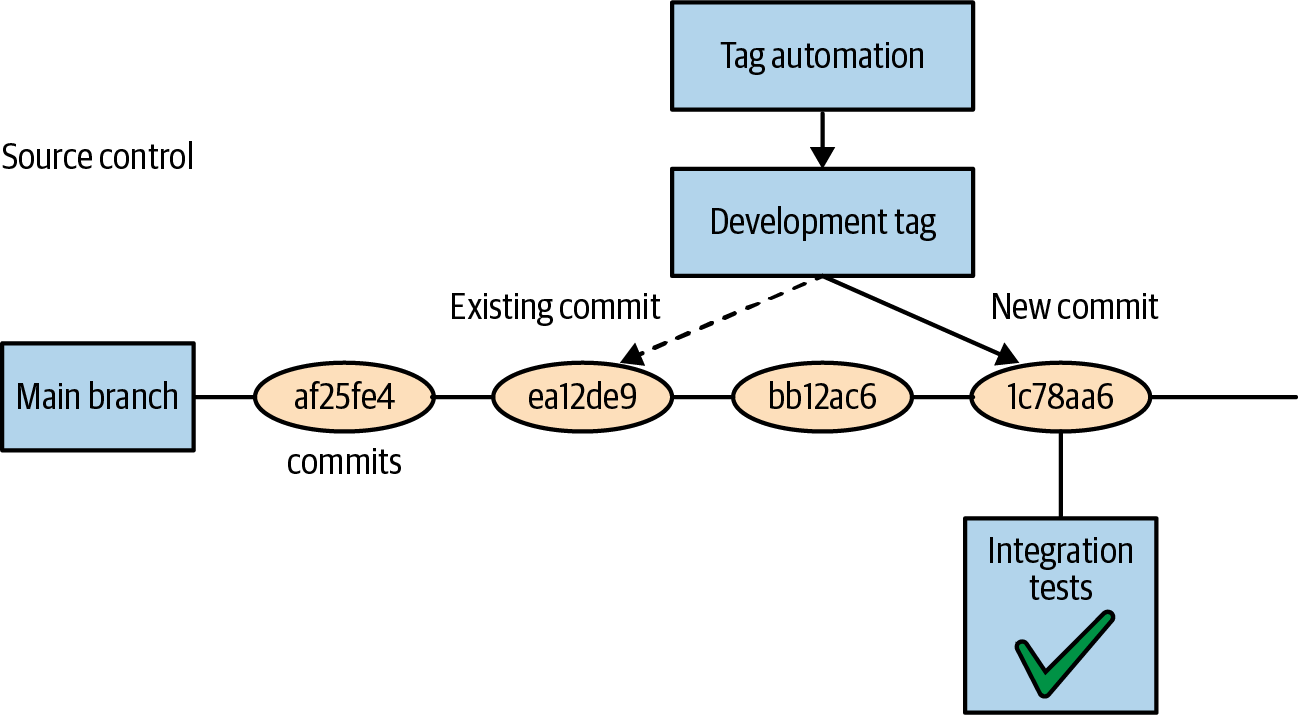
在版本修订(revisions)和阶段(stages)之间建立映射关系。
在文件系统方案中,可以使用符号链接(symbolic link)来完成阶段到版本的映射,例如:
frontend/
canary/ -> v2/
release/ -> v1/
v1/
frontend-deployment.yaml
...在版本控制系统(如 Git)中,这个机制更加直接:
在某个版本修订上增加一个额外的 tag,该 tag 指向当前阶段所对应的版本,都指向同一个 commit。
v1.0
release参数化环境的做法是:一份 YAML 模板 + 多份参数文件 → 自动生成不同环境的 YAML
存放大部分共享配置,例如:
deployment.yaml.tpl
service.yaml.tpl
configmap.yaml.tpl这些内容在:
基本都一样。
只存少量差异,比如:
replicas: 2
image: myapp:dev
cpu: 200m
memory: 256Mireplicas: 10
image: myapp:v1.2.0
cpu: 1
memory: 1Gi模板 = 共享逻辑, 参数 = 环境差异, 组合后生成最终 YAML。
现实工程里基本不会自己手写模板引擎,而是用现成工具:
Helm,最常见,
templates/deployment.yaml
values.yaml
# 运行
helm template
helm install
# 自动生成YAMLHelm 模板语法,Helm 使用的是 mustache(胡子模板)语法:
metadata:
name: {{ .Release.Name }}-deployment传入参数
Release:
Name: my-release写一个 YAML 模板 + 写一个参数文件 → 自动生成最终 YAML
把每个部署生命周期看作是:
参数文件(parameters file) + 指向某个具体版本的指针(pointer to a specific version) 的组合
用哪一套模板版本 + 哪一套参数
基于目录的布局(directory-based layout)
frontend/
staging/
templates -> ../v2
staging-parameters.yaml
production/
templates -> ../v1
production-parameters.yaml
v1/
frontend-deployment.yaml
frontend-service.yaml
v2/
frontend-deployment.yaml
frontend-service.yaml
...环境 = 模板 + 参数你的应用不能只活在一个机房里,否则哪天这个机房挂了,你的用户就会顺带一起消失。
版本 (v1, v2, v3)
↓
阶段 (dev, staging, canary, prod)
↓
区域 (Tokyo, Singapore, US, Europe...)最终组合 版本 × 阶段 × 区域
v2 + prod + tokyo
v2 + prod + singapore
v2 + prod + us
v2 + canary + tokyo
v3 + staging + us当你在小规模开发时,这个概念可能听起来有点奇怪,但在中型或大型规模下,你很可能会遇到一个重要问题:不同地区部署着不同版本的应用程序。
这种情况可能由于各种原因发生(例如某次发布在某个地区失败、被中止,或者在特定地区出现问题),如果你不仔细跟踪,很快就会演变成一个全球各地部署着不同版本、难以管理的雪花系统(snowflake)。
更进一步,当客户询问他们遇到的 bug 是否已经修复时,一个常见的问题就会变成:
“这个修复已经部署了吗?”
构建仪表盘(Dashboard)和监控系统是至关重要的。 仪表盘应该能够让你一眼看出每个地区正在运行哪个版本,同时还需要告警机制(Alerting),当系统中部署的应用版本过多时触发警报。
强调了组织应用时应遵循的基础原则:
假设集群有四个节点。可以建立一个由三个节点组成的集群,如果你愿意,甚至可以建立一个由一百个节点组成的集群,但四个节点是一个相当不错的数字。
默认的 Ubuntu 20.04 镜像支持 Raspberry Pi 4,也是许多 Kubernetes 集群常用的操作系统。
首先要做的是只启动 API 服务器节点。组装你的集群,并决定哪个是 API 服务器节点。插入存储卡,将电路板插入 HDMI 输出端,将键盘插入 USB 端口。
接下来,接通电源,启动电路板。在提示符下登录,使用用户名 ubuntu和密码 ubuntu.
在 API 服务器上设置网络。为 Kubernetes 集群设置网络可能很复杂。
在下面的示例中,我们正在设置一个网络,其中一台机器使用无线网络连接到互联网;这台机器还通过有线以太网连接到集群网络,并提供一个 DHCP(动态主机配置协议)服务器,为集群中的其余节点提供网络地址。 该网络的示意图如图所示:
/etc/netplan/50-cloud-init.yaml
文件。如果该文件不存在,可以创建它。
network:
version: 2
ethernets:
eth0:
dhcp4: false
dhcp6: false
addresses:
- '10.0.0.1/24'
optional: true
wifis:
wlan0:
access-points:
<your-ssid-here>:
password: '<your-password-here>'
dhcp4: true
optional: true这样就可以将主以太网接口设置为静态分配地址
10.0.0.1,并将 WiFi 接口设置为连接本地 WiFi。然后运行
sudo netplan apply 以获取这些新更改。
重新启动机器,获取 10.0.0.1 地址。运行ip addr 并查看eth0
接口的地址,即可验证设置是否正确。还可验证与互联网的连接是否正常。
接下来,我们要在这个 API 服务器上安装 DHCP,这样它就能为工作节点分配地址。运行:
$ apt-get install isc-dhcp-server然后按如下方式配置 DHCP
服务器(/etc/dhcp/dhcpd.conf):
# Set a domain name, can basically be anything
option domain-name "cluster.home";
# Use Google DNS by default, you can substitute ISP-supplied values here
option domain-name-servers 8.8.8.8, 8.8.4.4;
# We'll use 10.0.0.X for our subnet
subnet 10.0.0.0 netmask 255.255.255.0 {
range 10.0.0.1 10.0.0.10;
option subnet-mask 255.255.255.0;
option broadcast-address 10.0.0.255;
option routers 10.0.0.1;
}
default-lease-time 600;
max-lease-time 7200;
authoritative;可能还需要编辑 /etc/default/isc-dhcp-server 文件,将
INTERFACES 环境变量设置为eth0
。使用sudo systemctl restart isc-dhcp-server 重启 DHCP
服务器。现在,你的机器应该可以发送 IP
地址了。您可以通过以太网将第二台机器连接到交换机上进行测试。第二台机器将从
DHCP 服务器获取 10.0.0.2 地址。
记得编辑/etc/hostname文件,将这台机器重命名为node-1
。为了帮助 Kubernetes 完成联网,你还需要设置iptables
,让它能看到桥接的网络流量。在/etc/modules-load.d/k8s.conf中创建一个只包含
br_netfilter 的文件。这将把br_netfilter 模块加载到内核中。
接下来,你需要为网络桥接和地址转换(NAT)启用一些systemctl 设置,这样
Kubernetes 网络就能正常工作,你的节点也能访问公共互联网。创建一个名为
/etc/sysctl.d/k8s.conf 的文件,并添加
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1然后编辑 /etc/rc.local(或类似文件),添加iptables
规则,将eth0 转发到wlan0
iptables -t nat -A POSTROUTING -o wlan0 -j MASQUERADE
iptables -A FORWARD -i wlan0 -o eth0 -m state \
--state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -i eth0 -o wlan0 -j ACCEPT基本的 Network
设置应该已经完成。插上其余两块板并接通电源(应该可以看到它们被分配了
10.0.0.3 和 10.0.0.4
地址)。编辑两台机器上的/etc/hostname文件,分别命名为
node-2 和node-3 。
首先查看 /var/lib/dhcp/dhcpd.leases,然后通过 SSH
连接到节点(再次记住首先更改默认密码)。验证节点是否可以连接到外部互联网。
在安装 Kubernetes 之前,你需要安装一个容器运行时。你可以使用几种可能的运行时,但最广泛采用的是来自 Docker 的containerd 。 containerd 由标准的 Ubuntu 软件包管理器提供,但其版本往往有些滞后。虽然比较费事,但我们建议从 Docker 项目本身安装。
# Add some prerequisites
sudo apt-get install ca-certificates curl gnupg lsb-release
# Install Docker's signing key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor \
-o /usr/share/keyrings/docker-archive-keyring.gpg最后一步,创建 /etc/apt/sources.list.d/docker.list
文件,内容如下:
deb [arch=arm64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] \
https://download.docker.com/linux/ubuntu focal stable现在你已经安装了 Docker
软件包仓库,可以通过运行以下命令来安装containerd.io 。重要的是要安装
containerd.io ,而不是containerd ,这样才能获得 Docker
软件包,而不是默认的 Ubuntu 软件包:
sudo apt-get update; sudo apt-get install containerd.io此时,containerd 已安装完毕,但您需要对其进行配置,因为软件包提供的配置无法与 Kubernetes 配合使用:
containerd config default > config.toml
sudo mv config.toml /etc/containerd/config.toml
# Restart to pick up the config
sudo systemctl restart containerd既然已经安装了容器运行时,就可以继续安装 Kubernetes 本身了。
你应该已经为所有节点设置了 IP 地址,并能访问互联网。 现在是时候在所有节点上安装 Kubernetes 了。使用 SSH 在所有节点上运行以下命令,安装kubelet 和kubeadm 工具。
首先,为软件包添加加密密钥:
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg \
| sudo apt-key add -然后将版本库添加到版本库列表中:
# echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
| sudo tee /etc/apt/sources.list.d/kubernetes.list最后,更新并安装 Kubernetes 工具。为了稳妥起见,这还会更新系统中的所有软件包:
# sudo apt-get update
$ sudo apt-get upgrade
$ sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni在 API服务器节点(运行 DHCP 并连接到互联网的节点)上运行:
$ sudo kubeadm init --pod-network-cidr 10.244.0.0/16 \
--apiserver-advertise-address 10.0.0.1 \
--apiserver-cert-extra-sans kubernetes.cluster.home请注意,您要宣传的是面向内部的 IP 地址,而不是外部地址。最后,它会打印出一条将节点加入集群的命令。它看起来类似于
$ kubeadm join --token=<token> 10.0.0.1以 SSH 登录群集中的每个工作节点,并运行该命令。完成所有操作后,您就可以运行此命令查看正在运行的集群了:
$ kubectl get nodes你已经建立了节点级网络,但仍需建立 Pod 之间的网络。由于集群中的所有节点都运行在同一个物理以太网网络上,因此只需在主机内核中设置正确的路由规则即可。
最简单的管理方法是使用 CoreOS 开发的Flannel 工具,现在
Flannel项目也支持该工具。 Flannel 支持多种不同的路由模式,我们将使用
host-gw 模式。您可以从Flannel 项目页面下载配置示例:
$ curl https://oreil.ly/kube-flannelyml \
> kube-flannel.yamlFlannel 提供的默认配置使用的是vxlan 模式。要解决这个问题,请用您喜欢的编辑器打开配置文件,将vxlan 替换为host-gw 。
您也可以使用sed 工具进行此操作:
$ curl https://oreil.ly/kube-flannelyml \
| sed "s/vxlan/host-gw/g" \
> kube-flannel.yaml更新kube-flannel.yaml文件后,就可以创建 Flannel 网络设置:
$ kubectl apply -f kube-flannel.yaml这将创建两个对象,一个是用于配置 Flannel 的 ConfigMap,另一个是实际运行 Flannel 守护进程的 DaemonSet。您可以使用
$ kubectl describe --namespace=kube-system configmaps/kube-flannel-cfg
$ kubectl describe --namespace=kube-system daemonsets/kube-flannel-ds此时,你应该已经在树莓派上运行了一个可用的 Kubernetes 集群。这对探索 Kubernetes 大有裨益。安排一些作业,打开用户界面,尝试通过重启机器或断开网络来破坏集群。